데이터 흝어보기 CCTV 데이터와 인구 통계를 가져와 필요한 데이터로 정제하겠습니다. import pandas as pd import numpy as np CCTV_Seoul = pd.read_csv('../data/01. Seoul_CCTV.csv', encoding = 'utf-8') CCTV_Seoul.head() 기관명 소계 2013년도 이전 2014년 2015년 2016년 0 강남구 3238 1292 430 584 932 1 강동구 1010 379 99 155 377 2 강북구 831 369 120 138 204 3 강서구 911 388 258 184 81 4 관악구 2109 846 260 390 613 CCTV_Seoul.tail() 기관명 소계 2013년도 이전 2014년 2015년 2016..
Pandas
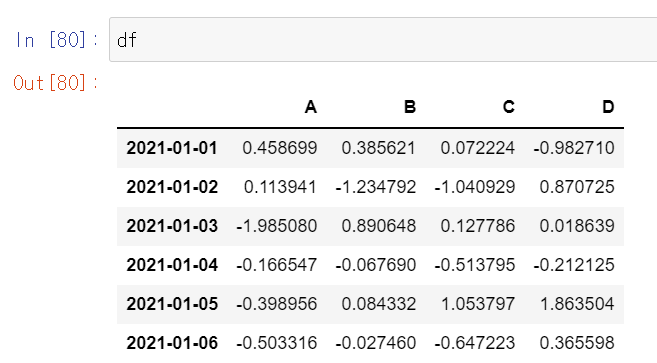
이전 게시물에 이어서 정리합니다. 1. 조건식 df['A'] > 0 # 칼럼 A에서 0보다 큰 숫자인지 boolean으로 반환합니다. df[df['A']>0] # 마스킹한다라고 합니다. df의 A 열 중 0보다 큰 값을 반환합니다. df[df>0] # df 안에서 0보다 큰 값을 반환합니다. 0보다 작은 값은 비워서 반환합니다. 2. 칼럼 추가, 수정 df['E'] = ["one","one","two","three","four","five"] # 칼럼 E를 추가합니다. df['E'] = ["one","one","two","three","four","new"] # 수정 마치 리스트에서 요소 바꾸는거 같네요. 3. 특정 요소가 있는지 확인 ( isin() ) df['E'].isin(["two"]) # 칼럼 ..
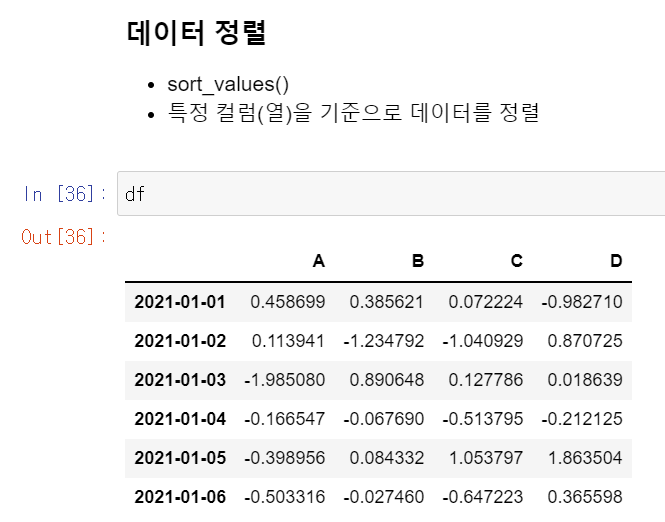
너무 길어지는거 같아서 데이터를 직접 건드는 것은 새롭게 게시글로 작성합니다. https://callmescone.tistory.com/127 [DS_study] pandas 기초, DataFrame 선언 및 정보 탐색 1. 쥬피터 안에서도 다큐멘터리를 볼 수 있습니다. 괄호 안에서 shift tab을 누르면 다음과 같이 함수에 대한 document가 뜹니다. 이걸 Docstring 이라 한다고 합니다. DataFrame에는 index, value, column 기본.. callmescone.tistory.com 다음의 데이터 프레임을 그대로 이어서 해보겠습니다. 1. 데이터 정렬 df.sort_values(by='B') # B열을 기준으로 오름차순으로 정렬합니다. # inplace 가 True면 원본데..

1. 먼저 numpy와 pandas를 불러옵니다. import pandas as pd import numpy as np 2. pd.Series() 가 도대체 뭐지? 다짜고짜 인수 없이 실행을 시켜보면 이렇게 어떤걸 넣어야 하는지 알려줍니다. 한번 알려준대로 넣어봅시다. 3. 구글링을 최대한 활용합시다. pandas Series 를 검색하면 document를 볼 수 있습니다. data로는 iterable, scalar, dict 등을 넣을 수 있고 dtype으로는 str, numpy.dtype 등이 가능하네요. optional 하기 때문에 안넣을 수도 있고요. 4. Document를 참고하여 코드를 작성해보겠습니다. 5. 데이터 타입이 다른 값을 넣어봅시다. int형과 str형을 넣었는데 dtype은 ob..