
이전 게시물에 이어서 정리합니다.
1. 조건식
df['A'] > 0 # 칼럼 A에서 0보다 큰 숫자인지 boolean으로 반환합니다.
df[df['A']>0] # 마스킹한다라고 합니다. df의 A 열 중 0보다 큰 값을 반환합니다.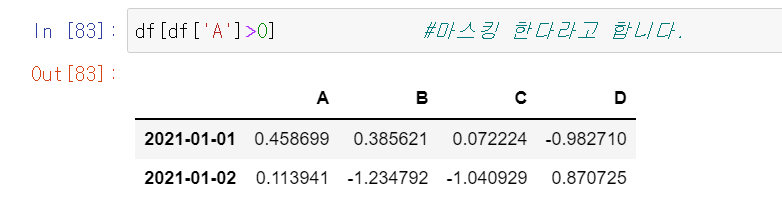
df[df>0] # df 안에서 0보다 큰 값을 반환합니다. 0보다 작은 값은 비워서 반환합니다.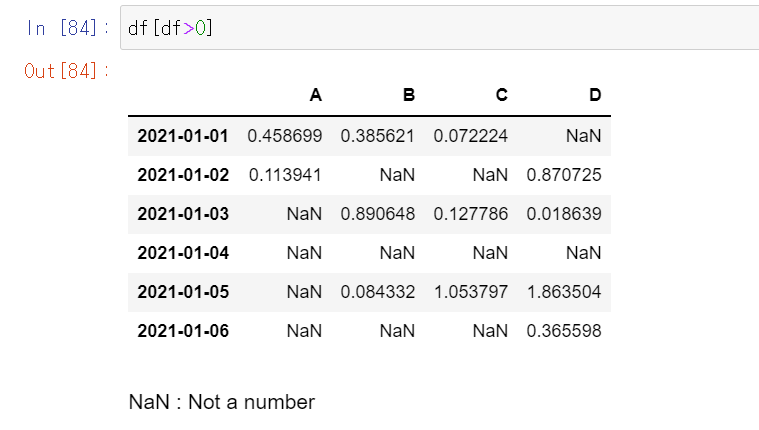
2. 칼럼 추가, 수정
df['E'] = ["one","one","two","three","four","five"] # 칼럼 E를 추가합니다.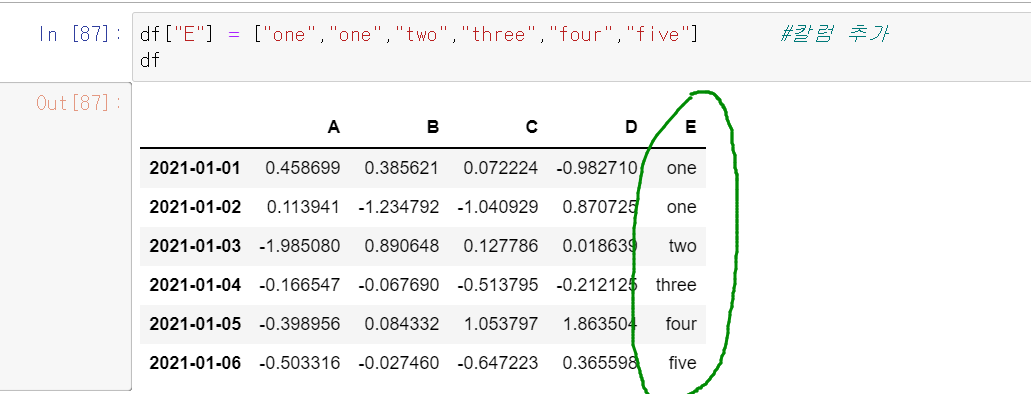
df['E'] = ["one","one","two","three","four","new"] # 수정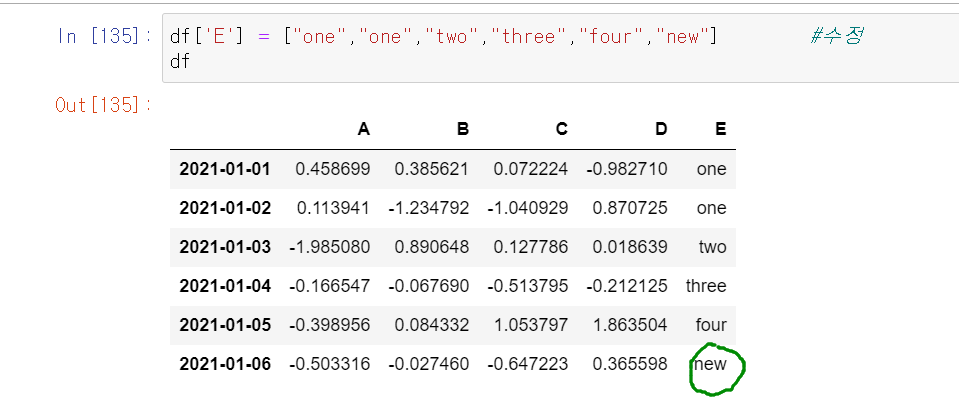
마치 리스트에서 요소 바꾸는거 같네요.
3. 특정 요소가 있는지 확인 ( isin() )
df['E'].isin(["two"]) # 칼럼 E 안에 two가 있는지 봅니다.
df[["E"]].isin(['two']) # 테이블을 만들어서 보여줍니다.
df['E'].isin(['two','four']) # two 와 four 가 있는지 확인합니다.
df[df['E'].isin(['two','four'])] # 조건식을 마스킹해주면, 조건에 해당하는 value를 반환합니다.
4. 특정 칼럼 제거 ( del, drop )
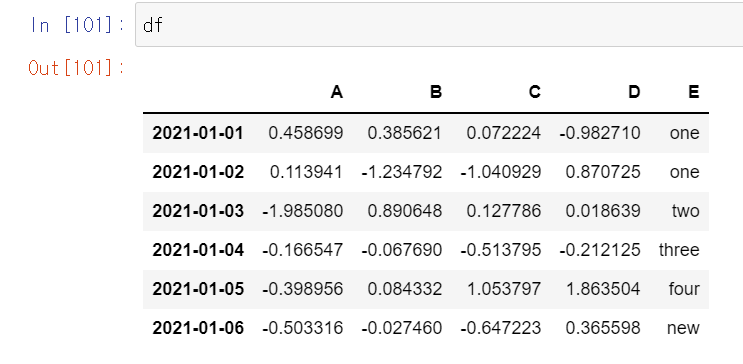
del df['E'] # E 열을 삭제 합니다.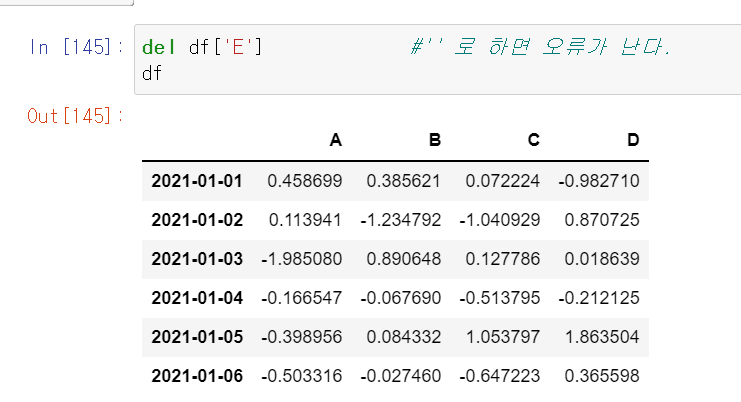
* '' 로 해도 오류 안납니다. 잘못 알고 저렇게 써놨어요
#axis = 0 가로, axis = 1 세로 (axis = 0 이 default)
df.drop(["D"]) # 행에는 'D' 가 없기 때문에 오류가 납니다.
df.drop(['D'], axis=1) # axis=1 이면 열 입니다. D 열을 제거 합니다.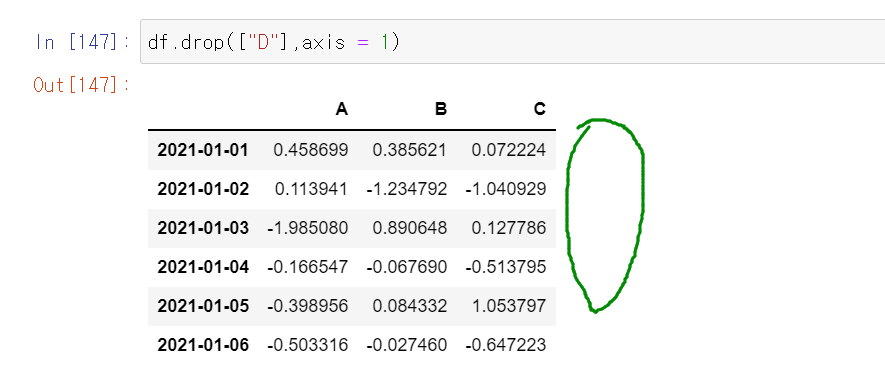
df.drop("20210105") # axis = 0 이 default, 01-05 행이 제거됩니다.
엥 근데 D가 제거가 안되어 있습니다. drop 은 비 파괴적 처리로, inplace = True를 넣어야 원본 데이터에 반영되는 모양입니다.
df.drop("20210105",inplace=True) #원본 데이터에 반영
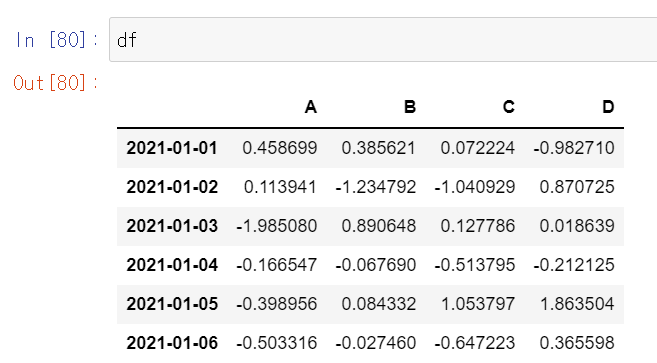
df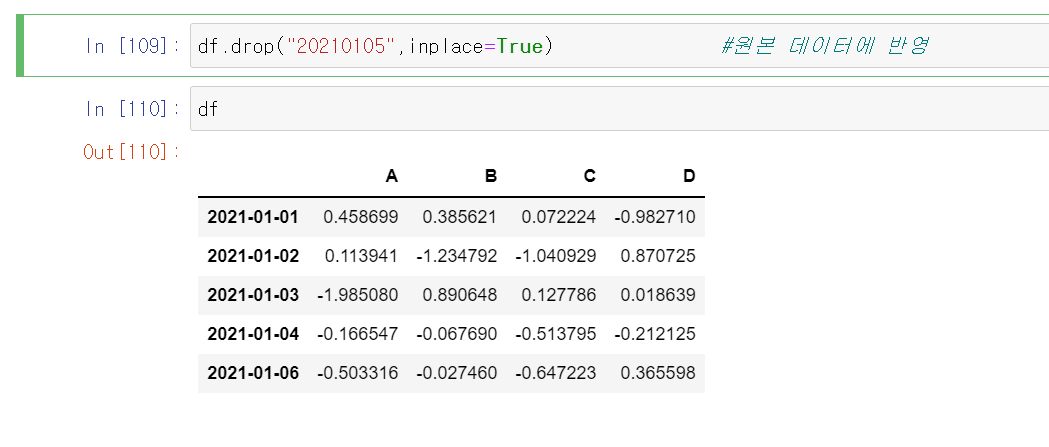
01-05 행이 사라져있습니다.
5. 함수 사용 ( apply() )
apply() 는 데이터 프레임에 함수 기능을 적용해주는 메소드라고 합니다.

# 기본 내장 함수
df['A'].apply("sum")
df['A'].apply("mean")
df['A'].apply("max"), df['A'].apply("min")
df[["A","D"]].apply("sum")
# pandas가 numpy 기반으로 된 라이브러리이기 때문에 넘파이의 대부분 함수는 다 적용될 수 있다.
df['A'].apply(np.sum)
df.apply(np.sum)
df['A'].apply(np.mean)
df.apply(np.mean)
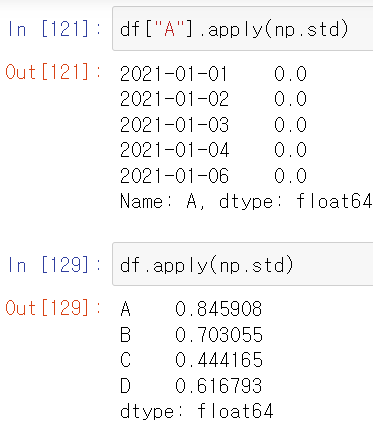
df['A'].apply(np.std)
df.apply(np.std)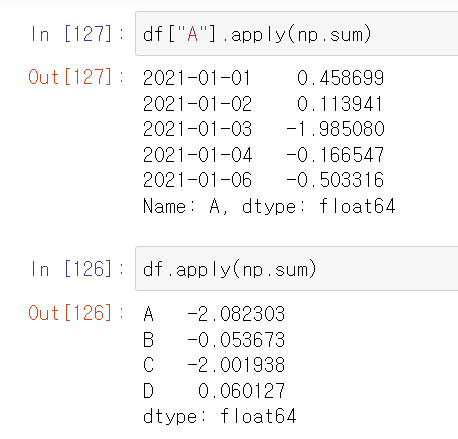

# 함수를 만들어서 적용시킬 수도 있습니다.
def plusminus(num):
return 'plus' if num>0 else 'minus'
df['A'].apply(plusminus)
# lambda도 물론 가능합니다.
df['A'].apply(lambda num : 'plus' if num>0 else 'minus')
🌮 배운 코드 정리
# 조건식
df['A'] > 0 # 칼럼 A에서 0보다 큰 숫자인지 boolean으로 반환합니다.
df[df['A']>0] # 마스킹한다라고 합니다. df의 A 열 중 0보다 큰 값을 반환합니다.
df[df>0] # df 안에서 0보다 큰 값을 반환합니다. 0보다 작은 값은 비워서 반환합니다.
# 칼럼 수정 또는 추가
df['E'] = ["one","one","two","three","four","five"] # 6행인 칼럼 E를 추가 또는 수정합니다.
# 칼럼 안에 요소가 있는지 확인
df['E'].isin(["two"]) # 칼럼 E 안에 two가 있는지 봅니다.
df['E'].isin(['two','four']) # two 와 four 가 있는지 확인합니다.
df[df['E'].isin(['two','four'])] # 조건식을 마스킹해주면, 조건에 해당하는 value를 반환합니다.
# 칼럼 제거
del df['E'] # E 열을 삭제 합니다. (파괴적 처리)
# 칼럼 또는 행 제거
df.drop(["D"]) #<---------- 에러, 행에는 'D' 가 없기 때문에 오류가 납니다.
df.drop(['D'], axis=1) # axis=1 이면, D 열을 제거 합니다.
df.drop("20210105") # axis = 0 이 default 입니다. 01-05 행이 제거됩니다.
df.drop("20210105",inplace=True) # inplace=True 가 있어야 원본 데이터에 반영됩니다.# 기본 내장 함수 적용
df['A'].apply("sum") # A 열 합
df['A'].apply("mean") # A 열 평균
df['A'].apply("max"), df['A'].apply("min") # A 열 최댓값, 최솟값
df[["A","D"]].apply("sum") # A 열 합, D 열 합# pandas가 numpy 기반으로 된 라이브러리이기 때문에 넘파이의 대부분 함수는 다 적용될 수 있다.
df['A'].apply(np.sum) # A 열 하나이기 때문에 A열 그대로 나온다.
df.apply(np.sum) # 각 열의 합
df['A'].apply(np.mean) # A 열 하나이기 때문에 A열 그대로 나온다.
df.apply(np.mean) # 각 열의 평균
df['A'].apply(np.std) # A 열 하나이기 때문에 표준편차는 0이다.
df.apply(np.std) # 각 열의 표준편차# 함수를 만들어서 적용시킬 수도 있습니다.
def plusminus(num):
return 'plus' if num>0 else 'minus'
df['A'].apply(plusminus) # 각 value에 대해 함수 적용
# lambda도 물론 가능합니다.
df['A'].apply(lambda num : 'plus' if num>0 else 'minus') # 각 value에 대해 함수 적용'DS_Study > 서울시 CCTV 현황' 카테고리의 다른 글
| [DS_study] pandas 데이터 합치기 (0) | 2022.05.29 |
|---|---|
| [DS_Study] 데이터 흝어보기 (0) | 2022.05.29 |
| [DS_study] pandas dataframe 정렬, 선택, 조회 (0) | 2022.05.25 |
| [DS_study] pandas 기초, DataFrame 선언 및 정보 탐색 (0) | 2022.05.25 |
| [DS_study] pandas 기초, pd.Series(), pd.date_range() (0) | 2022.05.25 |