
Hook
- register_foward_pre_hook
- hook(module, input)
- register_foward_hook
- hook(module, input, output)
- register_full_backward_pre_hook
- register_full_backward_hook
- hook(module, grad_input, grad_output)
모델 불러오기
- model.save()
- 학습 결과 저장
- 아키텍쳐와 파라메터 저장
- 중간 과정 저장을 통해 최선의 결과 모델을 선택
- 외부 연구자와 공유하여 학습 재연성 향상
print("Model's state_dict:") # state_dict : 모델의 파라미터 표시 for param_tensor in model.state_dict(): print(param_tensor, "\\t", model.state_dict()[param_tensor].size()) # state_dict를 저장 torch.save(model.state_dict(), os.path.join(MODEL_PATH, "model.pt")) # 같은 모델의 형태에서는 파라메터만 load new_model = TheModelClass() new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt"))) # 모델의 architecture와 함께 저장 torch.save(model, os.path.join(MODEL_PATH, "model.pt")) # 모델의 architecture와 함께 load model = torch.load(os.path.join(MODEL_PATH, "model.pt"))- 모델을 불러올 때, 동일한 코드로 동일한 모델이어야 한다.
new_model = TheModel() new_model.loadstate_dict(torch.load(os.path.join(MODEL_PATH), "model.pt"))) # <ALL keys matched successfully> - checkpoints
- 학습의 중간결과
- earlystopping 기법 사용시 이전 학습의 결과물을 저장.
- loss와 metric 값을 지속적으로 확인, 저장
- 일반적으로 epoch, loss, metric을 함께 저장하여 확인
torch.save({ 'epoch' : e, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': epoch_loss, }, f'saved/checkpoint_model_{e}_{epoch_loss/len(dataloader}_{epoch_acc/len(dataloader)}.pt') checkpoint = torch.load(PATH) model.load_state_dict(checkppoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss']
Transfer Learning
- Transfer Learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 대용량 데이터셋으로 만들어진 좋은 성능의 모델
- 현재의 DL에서는 일반적인 학습 기법
- Backbone architecture 가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함.
- https://github.com/huggingface/pytorch-image-models
- NLP는 허깅페이스가 사실상 표준
- Frezzing
- pretrained model 활용시 모델의 일부분을 frozen 시킴.
- stepping frozen 등 다양한 기법
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
# defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
# frozen
for param in my_model.parameters():
param.requires_grad = False
# 내가 만든 마지막 레이어
for param in my_model.linear_layers.parameters():
param.requires_grad = True
Monitoring tools for PyTorch
- Tensorboard
- scalar : metric 등 상수 값의 연속(epoch)을 표시
- graph : 모델의 computational graph 표시
- histogram : weight 등 값의 분포로 표현
- image, text : 예측 값과 실제 값을 비교 표시
- mesh : 3d 형태의 데이터를 표현하는 도구
from torch.utils.tensorboard import SummaryWriter import numpy as numpy # 기록 생성 객체 writer = SummaryWriter(logs_base_dir) # scalar 값 기록 # Loss/train : loss category 에 train 값, n_iter : x 축의 값. for n_iter in range(100): writer.add_scalar('Loss/train', np.random.random(), n_iter) writer.add_scalar('Loss/test', np.random.random(), n_iter) writer.add_scalar('Accuracy/train', np.random.random(), n_iter) writer.add_scalar('Accuracy/test', np.random.random(), n_iter) writer.flush() # 값을 기록 # 쥬피터 노트북 내에서 사용 %load_ext tensorboard # 포트로 띄움. %tensorboard --logdir {logs_base_dir} - wandb(weight & biases)
- MLOps의 대표적인 (유료/무료)
- 협업, code versioning, 실험결과 기록 등
- setting > api key 복사, project 생성(project 이름도 정해서)
Multi-GPU 학습
DSWP(2005-2018) $<10^5$ | CETI $<4*10^9$ | BERT(2018) $<2.5 * 10^9$ | GPT-2(2019) $<10^{10}$ | GPT-3(2020) $<10^{11}$|
- 용어
- Single Node Single GPU
- Single Node Multi GPU
- Multi Node Multi GPU ex) 서버실
- TensorRT (Nvidia)
- Model parallel
- 모델을 크게 만들기 위해 사용하는 병렬 GPU
- 모델의 병목, 파이프라인의 어려움 → 고난이도 과제
![]()
Alexnet

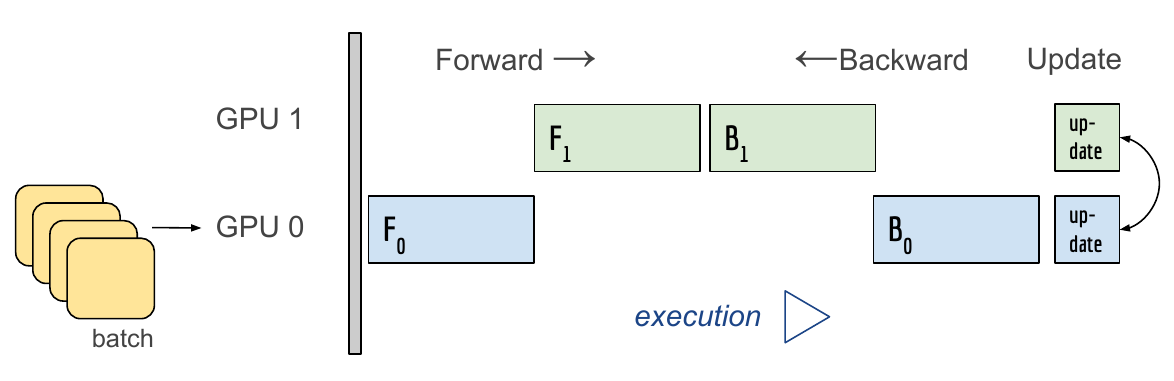
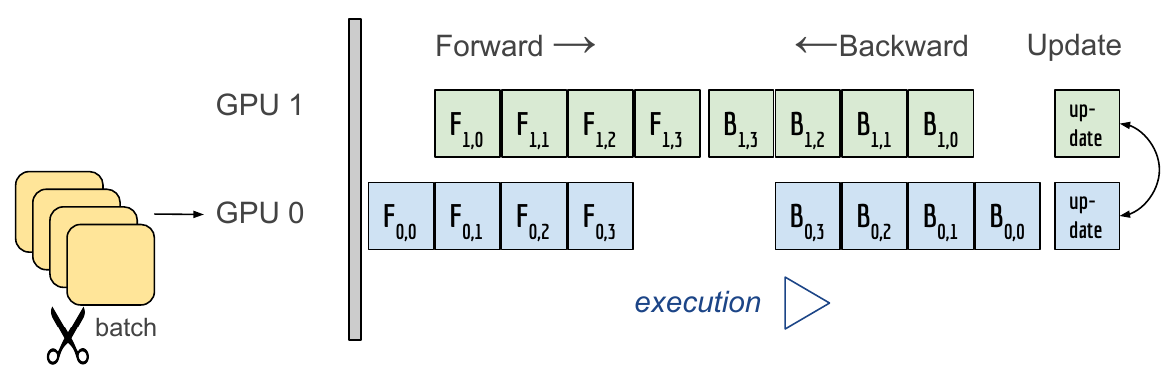
- Data Parallel
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- minibatch와 유사한 수식
- 기본적인 방식
- Foward
- Data 쪼개기
- Model duplicate
- 연산 실행 및 처리
- 한곳에 연산 결과를 모아줌.
- global interpreter Lock (파이썬이 갖고있는 제약)
- Backward
- 모은 연산 결과를 가지고 각각의 Loss 및 Gradient 계산
- grad를 GPU 각각에 나눠줌
- 각각의 GPU들이 Backward
- 업데이트 된 gradients를 다시 한데 모아줌
- Foward
- GPU 사용 불균형 문제 발생 (데이터/메모리 분산 불균형 문제)
- 한 GPU가 병목 → 해당 GPU로 인해, 그에 맞춰 전 Batch 사이즈의 감소
- GIL ( Global Interpreter Lock )
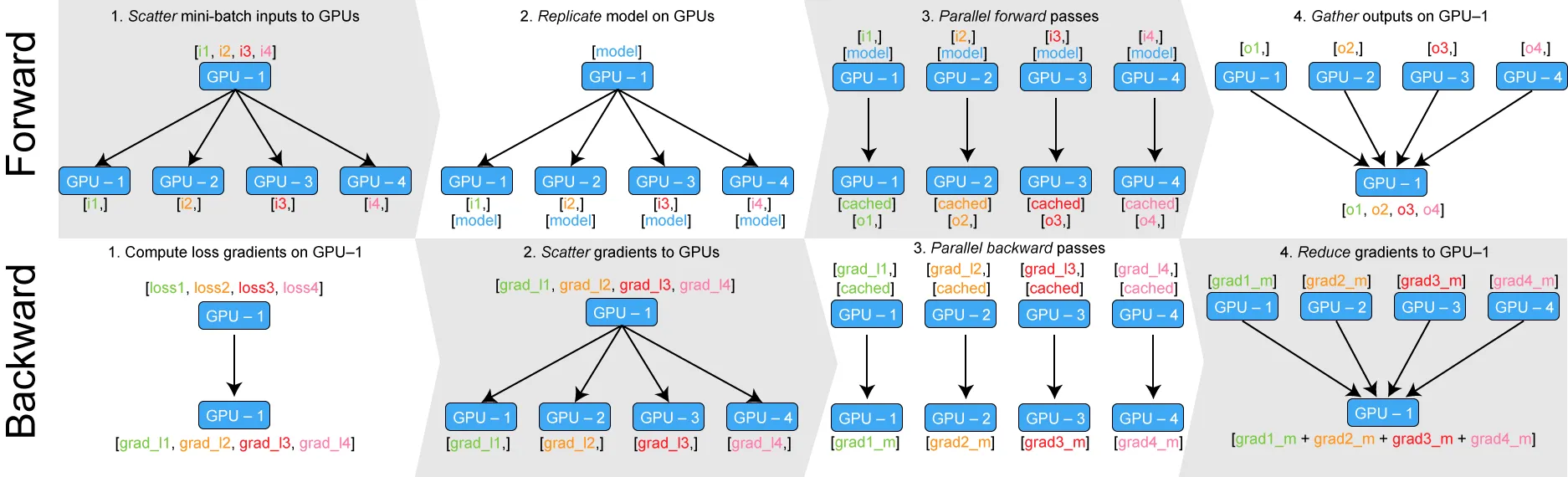
- Pytorch 에서 제공하는 방식
- DataParallel - 위의 기본적인 방식 (데이터 분배 후 평균)
# Encasulate the model <<<< 이거 하나가 전부
parallel_model = torch.nn.DataParallel(model)
predictions = parallel_model(inputs)
loss =loss_functoin(predictions, laels)
loss.mean().backward()
optimizer.step()
predictions = parallel_model(inputs)- DistributedDataParallel
- GPU 뿐만 아니라 CPU 를 사용하여 coordinate
- 중간에 한 데 모으는 과정이 없음.
- 연산 다 끝나고 gradients 를 모아 평균.
# DistributedDataParallel 사용하는 법
# sampler 사용
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
pin_memory = True # d램에 바로바로 데이터를 올릴 수 있도록 절차를 간소화 하는 방식
# num_workes : 보통 GPU * 4
trainloader = torch.utils.data.DataLoader(train_data,
batch_size=20,
shuffle = False,
pin_memory=pin_memory,
num_workers=3,
sampler=train_sampler
)
#----------------------------------------------------------------------------------------------------#
def main():
n_gpus = torch.cuda.device_count()
torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus, ))
# n_gpus : 프로세싱의 갯수 (gpu 갯수)
def main_worker(gpus, n_gpus):
image_size = 224
batch_size = 512
num_worker = 8
epoch = ..
batch_size = int(batch_size / n_gpus)
num_worker = int(num_worker / n_gpus)
# 멀티프로세싱 통신 규약 정의
torch.distributed.init_process_group(
backend='nccl',
init_method='tcp://127.0.0.1:2568',
world_size=n_gpus,
rank=gpus)
model = MODEL
torch.cuda.set_device(gpu)
model = model.cuda(gpu)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
#------------------------------------------------------------------------------------------------------#
# 파이썬의 멀티프로세싱 코드예
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p :
print(p.map(f,[1,2,3])
- https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255
- Reference
💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups…
medium.com
Multi GPU with Pytorch (DistributedDataParallel)
1. Introduction 많은 연구자 및 개발자들이 관심을 갖는 주제 중 하나는 Deep Learning 모델을 빠르게 학습시키는 방법입니다. 일반적으로 Deep Learning 모델을 빠르게 학습시키는 방법에는 여러가지가 있
blog.si-analytics.ai
- Transfer Learning이 무엇인가요? 그리고 FIne-Tuning과의 차이는 무엇일까요?
- Transfer Learning 은 pre-trained model 을 가져와 다른 도메인의 데이터로 다시 학습 시키는 것을 말합니다. 전이학습을 할 경우 선, 점, 곡선 등의 low level 특성들을 보다 잘 감지할 수 있기 때문에 적은 데이터셋으로도 효과를 극대화 시킬 수 있는 학습 방법으로 알려집니다. Fine-Tuning은 전이 학습의 방법 중 하나로 미세한 조정을 더하는 방식 입니다. 가령 pretrained-model에 output-layer을 붙여 더 많은 카테고리를 분류한다던가, 더하는 레이어만 별도 추가 학습 시켜 데이터 수가 부족한 점을 보완한다던가, 또는 학습률을 조정한다던가 하는 방식이 이에 해당할 수 있습니다.
- GIL이 무엇이고 Data Parallel과 어떤 관련이 있는지 작성해주세요.
- Global Interpreter Lock은 여러 개의 스레드가 파이썬 바이트 코드를 한번에 하나만 사용할 수 있게 락을 거는 것을 의미합니다. 이는 파이썬의 메모리 안전성을 보장하기 위한 장치 이지만, 그로 인해 멀티 스레딩 중 병목현상이 발생할 수 있습니다. DataParallel은 단일 작업, 멀티쓰레드 이기 때문에 쓰레드간 GIL 경합, 복제 모델의 반복 당 생성, 산란 입력 및 수집 출력으로 인한 추가적인 오버헤드가 발생할 수 있는 것입니다.
- 답안 출처 : https://tutorials.pytorch.kr/intermediate/ddp_tutorial.html
- DistributedDataParallel(DDP) 와 DataParallel 의 차이점이 뭔지 설명해주세요.
- DDP는 각 CPU 마다 프로세스를 생성하여 개별 GPU에 할당합니다. 이 방식은 GPU에서 독립적으로 모델 학습을 진행할 수 있또록 해줍니다. 더 효율적인 GPU 메모리 사용 및 더 나은 확장성을 제공합니다. 반면에 DataParallel은 하나의 주 CPU 프로세스에서 여러 GPU로 모델과 데이터를 복사하여 병렬 처리를 수행 합니다. 그러나 이는 GPU 간의 통신 오버헤드와 GPU 사용의 불균형을 야기할 수 있습니다.
- DDP는 각 CPU 마다 프로세스를 생성하여 개별 GPU에 할당합니다. 이 방식은 GPU에서 독립적으로 모델 학습을 진행할 수 있또록 해줍니다. 더 효율적인 GPU 메모리 사용 및 더 나은 확장성을 제공합니다. 반면에 DataParallel은 하나의 주 CPU 프로세스에서 여러 GPU로 모델과 데이터를 복사하여 병렬 처리를 수행 합니다. 그러나 이는 GPU 간의 통신 오버헤드와 GPU 사용의 불균형을 야기할 수 있습니다.
'근황 토크 및 자유게시판 > TIL' 카테고리의 다른 글
| [딥러닝 기초 다지기] 부트캠 day-15 (2) | 2023.11.21 |
|---|---|
| [Pytorch] 네부캠 day-12 (0) | 2023.11.17 |
| [Pytorch] 네부캠 day-10 (1) | 2023.11.16 |
| [Pytorch] 부트캠 day-9 (1) | 2023.11.15 |
| [Pytorch] 부트캠 day-8 (1) | 2023.11.14 |
Hook
- register_foward_pre_hook
- hook(module, input)
- register_foward_hook
- hook(module, input, output)
- register_full_backward_pre_hook
- register_full_backward_hook
- hook(module, grad_input, grad_output)
모델 불러오기
- model.save()
- 학습 결과 저장
- 아키텍쳐와 파라메터 저장
- 중간 과정 저장을 통해 최선의 결과 모델을 선택
- 외부 연구자와 공유하여 학습 재연성 향상
print("Model's state_dict:") # state_dict : 모델의 파라미터 표시 for param_tensor in model.state_dict(): print(param_tensor, "\\t", model.state_dict()[param_tensor].size()) # state_dict를 저장 torch.save(model.state_dict(), os.path.join(MODEL_PATH, "model.pt")) # 같은 모델의 형태에서는 파라메터만 load new_model = TheModelClass() new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt"))) # 모델의 architecture와 함께 저장 torch.save(model, os.path.join(MODEL_PATH, "model.pt")) # 모델의 architecture와 함께 load model = torch.load(os.path.join(MODEL_PATH, "model.pt"))- 모델을 불러올 때, 동일한 코드로 동일한 모델이어야 한다.
new_model = TheModel() new_model.loadstate_dict(torch.load(os.path.join(MODEL_PATH), "model.pt"))) # <ALL keys matched successfully> - checkpoints
- 학습의 중간결과
- earlystopping 기법 사용시 이전 학습의 결과물을 저장.
- loss와 metric 값을 지속적으로 확인, 저장
- 일반적으로 epoch, loss, metric을 함께 저장하여 확인
torch.save({ 'epoch' : e, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict(), 'loss': epoch_loss, }, f'saved/checkpoint_model_{e}_{epoch_loss/len(dataloader}_{epoch_acc/len(dataloader)}.pt') checkpoint = torch.load(PATH) model.load_state_dict(checkppoint['model_state_dict']) optimizer.load_state_dict(checkpoint['optimizer_state_dict']) epoch = checkpoint['epoch'] loss = checkpoint['loss']
Transfer Learning
- Transfer Learning
- 다른 데이터셋으로 만든 모델을 현재 데이터에 적용
- 대용량 데이터셋으로 만들어진 좋은 성능의 모델
- 현재의 DL에서는 일반적인 학습 기법
- Backbone architecture 가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행함.
- https://github.com/huggingface/pytorch-image-models
- NLP는 허깅페이스가 사실상 표준
- Frezzing
- pretrained model 활용시 모델의 일부분을 frozen 시킴.
- stepping frozen 등 다양한 기법
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained=True)
self.linear_layers = nn.Linear(1000, 1)
# defining the forward pass
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
# frozen
for param in my_model.parameters():
param.requires_grad = False
# 내가 만든 마지막 레이어
for param in my_model.linear_layers.parameters():
param.requires_grad = True
Monitoring tools for PyTorch
- Tensorboard
- scalar : metric 등 상수 값의 연속(epoch)을 표시
- graph : 모델의 computational graph 표시
- histogram : weight 등 값의 분포로 표현
- image, text : 예측 값과 실제 값을 비교 표시
- mesh : 3d 형태의 데이터를 표현하는 도구
from torch.utils.tensorboard import SummaryWriter import numpy as numpy # 기록 생성 객체 writer = SummaryWriter(logs_base_dir) # scalar 값 기록 # Loss/train : loss category 에 train 값, n_iter : x 축의 값. for n_iter in range(100): writer.add_scalar('Loss/train', np.random.random(), n_iter) writer.add_scalar('Loss/test', np.random.random(), n_iter) writer.add_scalar('Accuracy/train', np.random.random(), n_iter) writer.add_scalar('Accuracy/test', np.random.random(), n_iter) writer.flush() # 값을 기록 # 쥬피터 노트북 내에서 사용 %load_ext tensorboard # 포트로 띄움. %tensorboard --logdir {logs_base_dir} - wandb(weight & biases)
- MLOps의 대표적인 (유료/무료)
- 협업, code versioning, 실험결과 기록 등
- setting > api key 복사, project 생성(project 이름도 정해서)
Multi-GPU 학습
DSWP(2005-2018) $<10^5$ | CETI $<4*10^9$ | BERT(2018) $<2.5 * 10^9$ | GPT-2(2019) $<10^{10}$ | GPT-3(2020) $<10^{11}$|
- 용어
- Single Node Single GPU
- Single Node Multi GPU
- Multi Node Multi GPU ex) 서버실
- TensorRT (Nvidia)
- Model parallel
- 모델을 크게 만들기 위해 사용하는 병렬 GPU
- 모델의 병목, 파이프라인의 어려움 → 고난이도 과제
![]()
Alexnet
- Data Parallel
- 데이터를 나눠 GPU에 할당 후 결과의 평균을 취하는 방법
- minibatch와 유사한 수식
- 기본적인 방식
- Foward
- Data 쪼개기
- Model duplicate
- 연산 실행 및 처리
- 한곳에 연산 결과를 모아줌.
- global interpreter Lock (파이썬이 갖고있는 제약)
- Backward
- 모은 연산 결과를 가지고 각각의 Loss 및 Gradient 계산
- grad를 GPU 각각에 나눠줌
- 각각의 GPU들이 Backward
- 업데이트 된 gradients를 다시 한데 모아줌
- Foward
- GPU 사용 불균형 문제 발생 (데이터/메모리 분산 불균형 문제)
- 한 GPU가 병목 → 해당 GPU로 인해, 그에 맞춰 전 Batch 사이즈의 감소
- GIL ( Global Interpreter Lock )
- Pytorch 에서 제공하는 방식
- DataParallel - 위의 기본적인 방식 (데이터 분배 후 평균)
# Encasulate the model <<<< 이거 하나가 전부
parallel_model = torch.nn.DataParallel(model)
predictions = parallel_model(inputs)
loss =loss_functoin(predictions, laels)
loss.mean().backward()
optimizer.step()
predictions = parallel_model(inputs)- DistributedDataParallel
- GPU 뿐만 아니라 CPU 를 사용하여 coordinate
- 중간에 한 데 모으는 과정이 없음.
- 연산 다 끝나고 gradients 를 모아 평균.
# DistributedDataParallel 사용하는 법
# sampler 사용
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
pin_memory = True # d램에 바로바로 데이터를 올릴 수 있도록 절차를 간소화 하는 방식
# num_workes : 보통 GPU * 4
trainloader = torch.utils.data.DataLoader(train_data,
batch_size=20,
shuffle = False,
pin_memory=pin_memory,
num_workers=3,
sampler=train_sampler
)
#----------------------------------------------------------------------------------------------------#
def main():
n_gpus = torch.cuda.device_count()
torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus, ))
# n_gpus : 프로세싱의 갯수 (gpu 갯수)
def main_worker(gpus, n_gpus):
image_size = 224
batch_size = 512
num_worker = 8
epoch = ..
batch_size = int(batch_size / n_gpus)
num_worker = int(num_worker / n_gpus)
# 멀티프로세싱 통신 규약 정의
torch.distributed.init_process_group(
backend='nccl',
init_method='tcp://127.0.0.1:2568',
world_size=n_gpus,
rank=gpus)
model = MODEL
torch.cuda.set_device(gpu)
model = model.cuda(gpu)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
#------------------------------------------------------------------------------------------------------#
# 파이썬의 멀티프로세싱 코드예
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p :
print(p.map(f,[1,2,3])
- https://medium.com/huggingface/training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups-ec88c3e51255
- Reference
💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups…
medium.com
Multi GPU with Pytorch (DistributedDataParallel)
1. Introduction 많은 연구자 및 개발자들이 관심을 갖는 주제 중 하나는 Deep Learning 모델을 빠르게 학습시키는 방법입니다. 일반적으로 Deep Learning 모델을 빠르게 학습시키는 방법에는 여러가지가 있
blog.si-analytics.ai
- Transfer Learning이 무엇인가요? 그리고 FIne-Tuning과의 차이는 무엇일까요?
- Transfer Learning 은 pre-trained model 을 가져와 다른 도메인의 데이터로 다시 학습 시키는 것을 말합니다. 전이학습을 할 경우 선, 점, 곡선 등의 low level 특성들을 보다 잘 감지할 수 있기 때문에 적은 데이터셋으로도 효과를 극대화 시킬 수 있는 학습 방법으로 알려집니다. Fine-Tuning은 전이 학습의 방법 중 하나로 미세한 조정을 더하는 방식 입니다. 가령 pretrained-model에 output-layer을 붙여 더 많은 카테고리를 분류한다던가, 더하는 레이어만 별도 추가 학습 시켜 데이터 수가 부족한 점을 보완한다던가, 또는 학습률을 조정한다던가 하는 방식이 이에 해당할 수 있습니다.
- GIL이 무엇이고 Data Parallel과 어떤 관련이 있는지 작성해주세요.
- Global Interpreter Lock은 여러 개의 스레드가 파이썬 바이트 코드를 한번에 하나만 사용할 수 있게 락을 거는 것을 의미합니다. 이는 파이썬의 메모리 안전성을 보장하기 위한 장치 이지만, 그로 인해 멀티 스레딩 중 병목현상이 발생할 수 있습니다. DataParallel은 단일 작업, 멀티쓰레드 이기 때문에 쓰레드간 GIL 경합, 복제 모델의 반복 당 생성, 산란 입력 및 수집 출력으로 인한 추가적인 오버헤드가 발생할 수 있는 것입니다.
- 답안 출처 : https://tutorials.pytorch.kr/intermediate/ddp_tutorial.html
- DistributedDataParallel(DDP) 와 DataParallel 의 차이점이 뭔지 설명해주세요.
- DDP는 각 CPU 마다 프로세스를 생성하여 개별 GPU에 할당합니다. 이 방식은 GPU에서 독립적으로 모델 학습을 진행할 수 있또록 해줍니다. 더 효율적인 GPU 메모리 사용 및 더 나은 확장성을 제공합니다. 반면에 DataParallel은 하나의 주 CPU 프로세스에서 여러 GPU로 모델과 데이터를 복사하여 병렬 처리를 수행 합니다. 그러나 이는 GPU 간의 통신 오버헤드와 GPU 사용의 불균형을 야기할 수 있습니다.
- DDP는 각 CPU 마다 프로세스를 생성하여 개별 GPU에 할당합니다. 이 방식은 GPU에서 독립적으로 모델 학습을 진행할 수 있또록 해줍니다. 더 효율적인 GPU 메모리 사용 및 더 나은 확장성을 제공합니다. 반면에 DataParallel은 하나의 주 CPU 프로세스에서 여러 GPU로 모델과 데이터를 복사하여 병렬 처리를 수행 합니다. 그러나 이는 GPU 간의 통신 오버헤드와 GPU 사용의 불균형을 야기할 수 있습니다.
'근황 토크 및 자유게시판 > TIL' 카테고리의 다른 글
| [딥러닝 기초 다지기] 부트캠 day-15 (2) | 2023.11.21 |
|---|---|
| [Pytorch] 네부캠 day-12 (0) | 2023.11.17 |
| [Pytorch] 네부캠 day-10 (1) | 2023.11.16 |
| [Pytorch] 부트캠 day-9 (1) | 2023.11.15 |
| [Pytorch] 부트캠 day-8 (1) | 2023.11.14 |