def program_A(x):
print('program A processing!')
return x + 3
def program_B(x):
print('program B processing!')
return x - 3
class Package(object):
"""프로그램 A와 B를 묶어놓은 패키지 코드"""
def __init__(self):
self.programs = [program_A, program_B]
# hooks
self.pre_hooks = []
self.hooks = []
def __call__(self, x):
for program in self.programs:
# pre_hook : 프로그램 실행 전에 날리는 훅
if self.pre_hooks:
for hook in self.pre_hooks:
output = hook(x) # 메소드가 return 값을 갖는 경우
if output:
x = output
x = program(x)
# hook : 프로그램 실행 이후 날리는 훅
if self.hooks:
for hook in self.hooks:
output = hook(x)
if output:
x = output
return x
# Hook - 프로그램의 실행 로직 분석 사용 예시
def hook_analysis(x):
print(f'hook for analysis, current value is {x}')
# 생성된 패키지에 hook 추가
package.hooks = []
package.hooks.append(hook_analysis)
이제 패키지 안의 program들이 실행 될 때마다, 실행 이후 current value인 x 값을 알려줄 것입니다. 앞으로는 디버깅 절대 이렇게 해야겠어요!!!!
torch.nn.Module
torch.nn.Module
딥러닝을 구성하는 Layer의 base class
Input, Output, Forward, Backward 정의
parameter 정의
nn.Parameter
Tensor 객체의 상속 객체
AutoGrad의 대상
nn.Module 내에서 attribute가 될 때는 required_grad=True 로 지정되어 학습 대상이 되는 Tensor
대부분의 layer에는 weights 값들이 지정되어 있기 때문에 우리가 지정할 일은 많지 않다.
Backward
Layer에 있는 Parameter들의 미분을 수행
Foward의 결과값 (model의 output=예측치)과 실제값 간의 차이(loss)에 대해 미분을 수행
해당 값으로 Parameter 업데이트
for epoch in range(epochs):
# Clear gradient buffers, 이전의 학습에 의해 영향받지 않기 위해
opitimizer.zero_grad()
# y hat
outputs = model(inputs)
loss = criterion(outputs, labels)
# get gradients w.r.t. to parameters
loss.backward()
# update parameters
optimizer.step()
실제 backward는 Module 단계에서 직접 지정 가능하다.
Module 에서 backward와 optimizer 오버라이딩
사용자가 직접 미분 수식을 써야하는 부담. → 순서에 대한 이해가 필요.
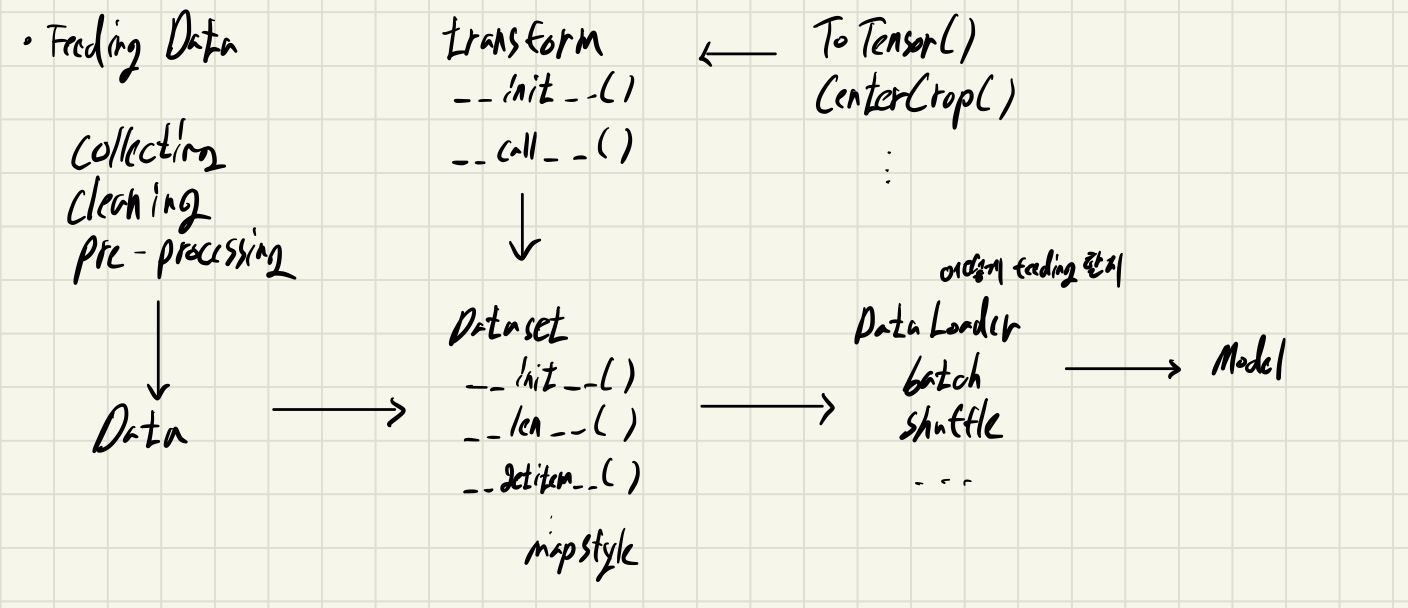
Dataset & DataLoader
Feeding data
Dataset
데이터의 입력 형태를 정의하는 클래스
데이터를 입력하는 방식의 표준화
Image, Text, Audio 등 데이터 타입에 따른 입력 정의.
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, text, labels):
self.labels = labels
self.data = text
self.length = len(labels)
def __len__(self):
return self.length
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
sample = {"Text":text, "Class":label}
return sample