
torch.nn.modules.linear
class Linear(nn.Module):
def __init__(self, in_features, out_features):
super().__init__()
self.W = Parameter(torch.ones(out_features, in_features))
self.b = Parameter(torch.ones(out_features))
def forward(self, x):
output = torch.addmm(self.b, x, self.W.T)
return output
x = torch.Tensor([[1, 2],
[3, 4]])
linear = Linear(2, 3)
linear(x)
'''
torch.Tensor([[4, 4, 4],
[8, 8, 8]]
'''
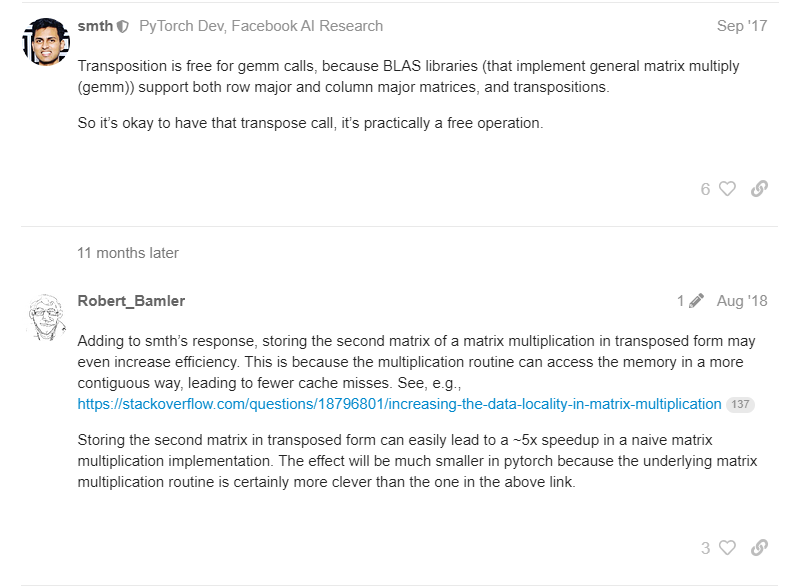
- Weight의 shape을 (in_features, out_features) 로 구현하지 않고, 굳이 (out_features, in_features) 구현한 후 Transpose 시켜 계산하는 이유
- Pytorch는 내부적으로 행렬 연산을 할 때, BLAS 라이브러리를 사용하기 때문에.
- Transpose 하여 행렬 곱을 연산할 경우, 메모리에 보다 연속적으로(contiguous) 접근할 수 있게 되므로 cahce miss를 줄여 더 효율적으로 작동할 수 있다.
- input_features를 열 표준 기준법(column-wise convention)에 따라 표현하기 위해.
nn.ModuleList
- nn.Sequential과의 차이점
- index로 접근도 할 수 있다.
- forward() method가 없다.
- 안에 담긴 module 간에 connection이 없다.
- Python list와의 차이점
- PyTorch에게 Module의 존재를 알려줄 수 있다.
- Python List에만 Module들을 넣어준다면, optimizer을 선언하고 model.parameter()로 parameter을 넘겨줄 때 “your model has no parameter” 과 같은 에러를 받게 된다.
- 만약 Python List에 넣어 모듈들을 보관했다면 반드시 nn.ModuleList로 wrapping 해줘야 한다.
- https://bo-10000.tistory.com/entry/nnModuleList
[PyTorch] nn.ModuleList 기능과 사용 이유
참고 : https://discuss.pytorch.org/t/when-should-i-use-nn-modulelist-and-when-should-i-use-nn-sequential/5463/3 When should I use nn.ModuleList and when should I use nn.Sequential? From what I see, it is interchangeable then? Unless there is some order t
bo-10000.tistory.com
Buffer
- Tensor v.s. Parameter v.s. Buffer항목 Tensor Parameter Buffer
| 항목 | Tensor | Parameter | Buffer |
| gradient 계산 | X | O | X |
| 값 업데이트 | X | O | X |
| 모델 저장 시 , 값 저장 | X | O | O |
- torch.nn.Module.register_parameter(name, param)
- register_parameter은 dict에 name이 있는지 없는지 사전 체크하는 반면, nn.Parameter 는 체크하지 않고 저장한다.
- torch.nn.Module.register_buffer(name, buffer)
- nn.Module의 register_buffer와 register_parameter의 차이점은 무엇입니까?
- nn.Parameter과 달리 register_parameter은 name(문자열) 을 전달하여 같이 저장하므로, 효과적으로 저장 및 찾을 수 있다.
- register_parameter 에 requires_grad=False라고 명시함으로써 register_buffer와 같은 기능을 수행할 수 있지만, optimizer에 전달하는 과정에서 이러한 버퍼들을 step() 메서드에서 불필요하게 건너뛰는 작업을 추가적으로 해야하므로, “clean code style” 을 위해서는 좋지 못하다.
Hook
- 특정 이벤트 후에 자동으로 실행되는 함수
- N개의 다른 페이지를 방문하면 웹사이트에 광고가 표시됩니다.
- 계좌에 자금이 추가되면 뱅킹 앱에서 알림을 보냅니다.
- 주변 조명이 감소하면 휴대폰의 화면 밝기 가 어두워집니다.
- 예시1 ) 오류 메시지의 원인을 찾으려고 모델에 인쇄 문을 삽입한적 있나요?
- 많은 경우 작업이 완료되면 인쇄문을 지우는 것을 잊어버리고, 이는 우리의 코드를 비전문적으로 보이게 만듭니다.
- 아래는 verboseExcution 클래스로 verbose 인스턴스를 만들고, 이후 foward를 통해 출력해보는 예시 입니다.
import torch from torchvision.models import resnet50 class VerboseExecution(nn.Module): def __init__(self, model: nn.Module): super().__init__() self.model = model # Register a hook for each layer for name, layer in self.model.named_children(): layer.__name__ = name layer.register_forward_hook( lambda layer, _, output: print(f"{layer.__name__}: {output.shape}") ) def forward(self, x: Tensor) -> Tensor: return self.model(x) verbose_resnet = VerboseExecution(resnet50()) dummy_input = torch.ones(10, 3, 224, 224) _ = verbose_resnet(dummy_input) # conv1: torch.Size([10, 64, 112, 112]) # bn1: torch.Size([10, 64, 112, 112]) # relu: torch.Size([10, 64, 112, 112]) # maxpool: torch.Size([10, 64, 56, 56]) # layer1: torch.Size([10, 256, 56, 56]) # layer2: torch.Size([10, 512, 28, 28]) # layer3: torch.Size([10, 1024, 14, 14]) # layer4: torch.Size([10, 2048, 7, 7]) # avgpool: torch.Size([10, 2048, 1, 1]) # fc: torch.Size([10, 1000]) - 예시2 ) feature를 추출하기 위해 모델을 다시 생성하시나요?
- 후크를 사용하면 기존 모델을 다시 생성할 필요 없이 feature를 추출할 수 있습니다.
- 아래는 FeatureExtractor을 통해 layer4와 avgpool 레이어 에서의 feature를 추출하는 예시 입니다.
from typing import Dict, Iterable, Callable class FeatureExtractor(nn.Module): def __init__(self, model: nn.Module, layers: Iterable[str]): super().__init__() self.model = model self.layers = layers self._features = {layer: torch.empty(0) for layer in layers} for layer_id in layers: layer = dict([*self.model.named_modules()])[layer_id] layer.register_forward_hook(self.save_outputs_hook(layer_id)) def save_outputs_hook(self, layer_id: str) -> Callable: def fn(_, __, output): self._features[layer_id] = output return fn def forward(self, x: Tensor) -> Dict[str, Tensor]: _ = self.model(x) return self._features resnet_features = FeatureExtractor(resnet50(), layers=["layer4", "avgpool"]) features = resnet_features(dummy_input) print({name: output.shape for name, output in features.items()}) # {'layer4': torch.Size([10, 2048, 7, 7]), 'avgpool': torch.Size([10, 2048, 1, 1])} - 예시3 ) Gradient Clipping 처리
- Pytorch에서는 Gradient Clipping을 처리하기 위한 여러 메서드를 제공하지만 후크를 사용하여 쉽게 수행할 수 도 있습니다.
- backprop 도중에 트리거 되므로, loss.backward() 를 통해 잘 작동되는지 확인합니다.
def gradient_clipper(model: nn.Module, val: float) -> nn.Module: for parameter in model.parameters(): parameter.register_hook(lambda grad: grad.clamp_(-val, val)) return model clipped_resnet = gradient_clipper(resnet50(), 0.01) pred = clipped_resnet(dummy_input) loss = pred.log().mean() loss.backward() print(clipped_resnet.fc.bias.grad[:25]) # tensor([-0.0010, -0.0047, -0.0010, -0.0009, -0.0015, 0.0027, 0.0017, -0.0023, # 0.0051, -0.0007, -0.0057, -0.0010, -0.0039, -0.0100, -0.0018, 0.0062, # 0.0034, -0.0010, 0.0052, 0.0021, 0.0010, 0.0017, -0.0100, 0.0021, # 0.0020]) - Pytorch lightening Model Hook
pytorch_lightning.core.hooks — PyTorch Lightning 1.8.6 documentation
Shortcuts
pytorch-lightning.readthedocs.io
T.M.I. 나의 감동 모먼트.




'근황 토크 및 자유게시판 > TIL' 카테고리의 다른 글
| [Pytorch] 네부캠 day-11 (0) | 2023.11.17 |
|---|---|
| [Pytorch] 네부캠 day-10 (1) | 2023.11.16 |
| [Pytorch] 부트캠 day-8 (1) | 2023.11.14 |
| [Pandas1] 부트캠 day-5 (0) | 2023.11.10 |
| [베이즈 정리] 부트캠 d-4 (0) | 2023.11.09 |