
순환 신경망을 이용해 주가 분석을 진행합니다.
Part1 - Data preprocessing
Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdImporting the training set
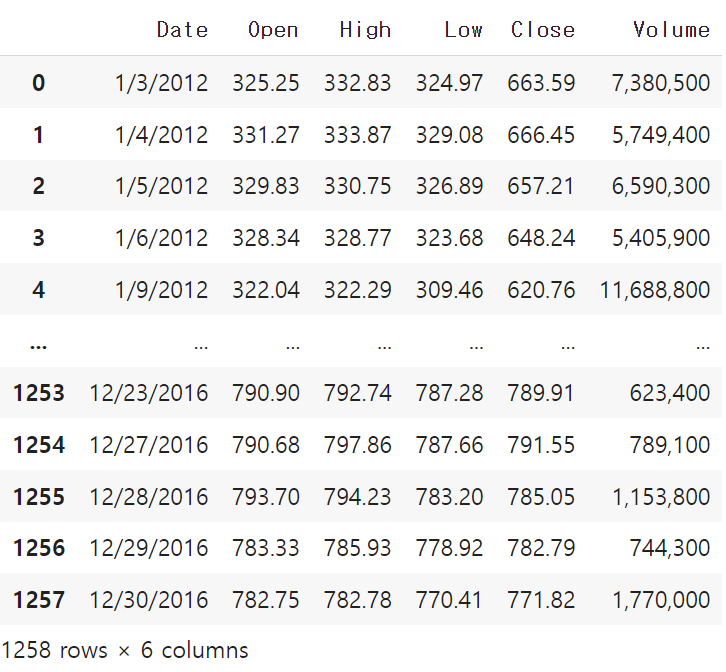
# open 열만 가져와서 넘파이 어레이 생성
# ((1258, 1), numpy.ndarray)
training_set = dataset_train.iloc[:, 1:2].valuesFeature Scaling
- Standardisation
$$ X_{standard} = {x - \text{mean}(x) \over \text{standard deviation(x)}} $$
- Normalization
$$ X_{norm} = {x - \text{min}(x) \over \text{max}(x) - \text{min}(x)}$$
# 순환 신경망의 출력층에 활성화 함수로 시그모이드 함수가 있는 경우, 정규화를 적용하는 것을 권장한다.
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range=(0,1))
training_set_scaled = sc.fit_transform(training_set)Creating a Data Structure with 60 timesteps and 1 output
# timesteps를 너무 적게 설정하면 과적합 또는 트랜드를 포착하지 못할 수 있다.
# 60일의 이전 주식시장(3개월)을 가지고 다음날 (T+1)의 주가를 예측해본다.
X_train = []
y_train = []
for i in range(60, len(training_set_scaled)) :
X_train.append(training_set_scaled[i-60:i,0])
y_train.append(training_set_scaled[i,0])
# T 기간의 이전 주가, T+1일날의 주가, 넘파이 배열 (1198, 60), (1198,)
X_train, y_train = np.array(X_train), np.array(y_train)Reshaping
https://keras.io/api/layers/recurrent_layers/rnn/
# 모델에 입력하기 위한 shape로 Reshaping
# (주가 수 or Batch Size, Time Steps, 지표 갯수 )
# (1198, 60, 1)
X_train = np.reshape(X_train, (X_train.shape[0],X_train.shape[1], 1))
Part2 - Building and Training the RNN
Importing the Keras libraries and packages
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import DropoutStacked LSTM with some dropout regularization
# 연속된 값 출력
regressor = Sequential()
# First LSTM
regressor.add(LSTM(units=50, # 50개 메모리 셀 (high Dimentionality)
return_sequences=True, # 뒤에 LSTM을 덧붙임
input_shape=(X_train.shape[1],1))) # (batch size(생략), timesteps, 지표 갯수)
regressor.add(Dropout(0.2)) # 20%의 뉴런을 누락, 50개 중 10개
# Second LSTM
regressor.add(LSTM(units=50, return_sequences=True))
regressor.add(Dropout(0.2))
# Third LSTM
regressor.add(LSTM(units=50, return_sequences=True))
regressor.add(Dropout(0.2))
# Fourth LSTM
regressor.add(LSTM(units=50, return_sequences=False))
regressor.add(Dropout(0.2))
# Output Layer (T+1기 주가)
regressor.add(Dense(units=1))
# Compile
# RMSprop, adam are recommended for RNN
regressor.compile(optimizer='adam', loss='mean_squared_error')
# Train
regressor.fit(X_train, y_train, epochs=100, batch_size=32)
Part 3 - Making the predictions and visualising the results
Getting the real and predicted stock price of 2017
# Concat Data
# train : 2012 ~ 2016, test : 2017.01
# (1278,)
dataset_total = pd.concat([dataset_train['Open'], dataset_test['Open']], axis=0)
inputs = dataset_total[len(dataset_total)-len(dataset_test)-60:].values
inputs = inputs.reshape(-1,1)
inputs.shape, dataset_test.shape
# 테스트 데이터에 정규화 적용
inputs = sc.transform(inputs)
# 테스트 데이터에 대한 입력값 구하기
X_test = []
for i in range(60,len(inputs)):
X_test.append(inputs[i-60:i, 0])
# (20, 60)
X_test = np.array(X_test)
# (20, 60, 1)
X_test = np.reshape(X_test,(X_test.shape[0],X_test.shape[1],1))
# predict
predicted_stock_price = regressor.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)Visualising the results
plt.plot(real_stock_price,color='red', label='Real Google Stock Price')
plt.plot(predicted_stock_price,color='blue', label='Predicted Google Stock Price')
plt.title('Google Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Google Stock Price')
plt.legend()
plt.show()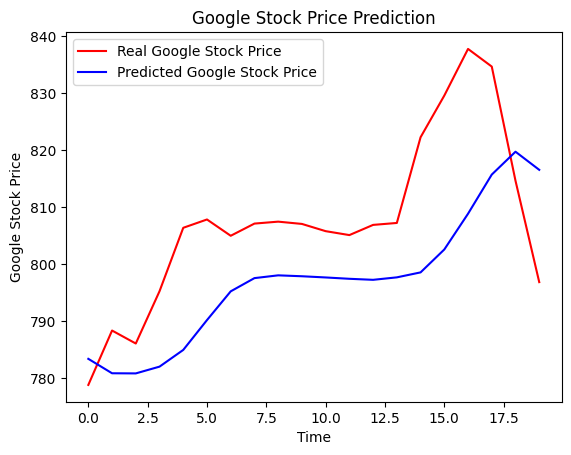
빠르고 비선형적인 변화는 단기적인 주가 변동으로, 브라운 운동에 따르면 과거 주가의 변동과 미래 주가의 변동은 서로 독립적이므로 우리 모델이 예측 못하는 것을 설명할 수 있다.
smooth change에 대해 우리 모델은 매우 잘 반응하고 있는 것으로 보인다. 추세적인 변화를 잘 포착하는 것으로 보인다.
Evaluation
import math
from sklearn.metrics import mean_squared_error
rmse = math.sqrt(mean_squared_error(real_stock_price,predicted_stock_price))
rmse/8000.0190126436138891
Enhancement Model
- 훈련 데이터를 더 모으기: 우리는 지난 5년의 구글 주가로 모델을 훈련했지만, 지난 10년의 데이터로 훈련하는 것이 훨씬 더 좋을 겁니다.
- 시점의 개수 늘리기: 모델은 다음 날의 주가를 예측하기 위해 60일의 전 거래일 주가를 기억했습니다. 시점을 60개(3개월)로 정했기 때문입니다. 시점의 개수를 예를 들어 120개(6개월)로 늘릴 수 있습니다.
- 다른 지표 추가하기: 다른 회사의 주가가 구글 주가와 연동된다는 직감이 들면 이 다른 주가를 훈련 데이터에 새로운 지표로 추가할 수 있습니다.
- LSTM층을 더 추가하기: 우리는 RNN을 4개의 LSTM층을 이용해 만들었지만 더 많이 추가할 수 있습니다.
- LSTM층에 뉴런 추가하기: 우리는 문제의 복잡성에 더 잘 반응하려면 LSTM 층에 많은 뉴런이 필요하다는 사실을 강조했고 4개의 LSTM 층 각각에 50개의 뉴런을 포함했습니다. 뉴런의 수를 늘릴 수 있습니다.
출처 : https://www.udemy.com/course/best-artificial-neural-networks/
'DL' 카테고리의 다른 글
| [History] 2018, ImageNet을 기반으로 하는 이미지 분류 알고리즘 리뷰 (0) | 2023.07.02 |
|---|---|
| [YOLO; You Only Look Once] Unified, Real-Time Object Detection (0) | 2023.06.29 |
| [Transformer] Attention is all you need (보완 예정) (0) | 2023.06.22 |
| [ResNet] Deep Residual Learning for Image Recognition (0) | 2023.06.22 |
| Docker를 통한 Jupyter Notebook 접속 (0) | 2023.05.04 |