
ImageNet Challenge
- 위키백과 정의
- 시각적 개체 인식 소프트웨어 연구에 사용 하도록 설계된 대규모 시각적 데이터베이스
- 1,400만 개 이상의 이미지에 어떤 물체가 그려져 있는지 나타내기 위해 손으로 주석을 달았음
- 최소 1백만 개의 이미지에서 BoundingBox 또한 제공
- 20,000개 이상의 범주가 포함되어 있으며 "풍선" 또는 "딸기"와 같은 일반적인 범주는 수백 개의 이미지로 구성
AlexNet (2012)
- 얀 르쿤 선생님의 1998년 논문에 영감을 받아 만들어지게 된, 최초의 딥러닝 모델
- 5개의 연속된 convolutional filters, max-pool layers 및 3 개의 Fully Connected Layers 가 있는 단순한 구조
- 2012 Image Net Challenge 에서 오류율 15.3% 기록, ( 26% 정확도를 지닌 이전 best 모델 SIFT 를 제침 )
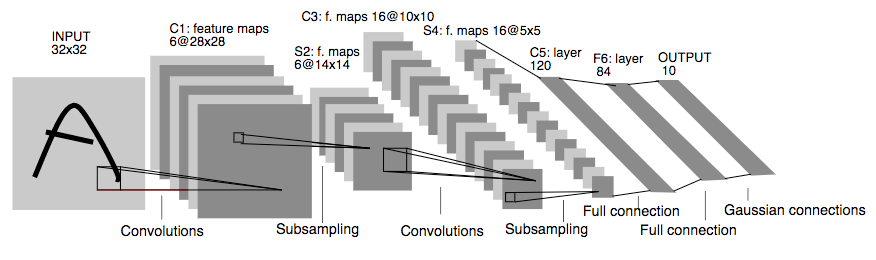

VGG 16 (2014)
- 16 개의 Conv. layers, 여러 개의 max-pool layers, 3개의 F.C.(Fully Connected) layers 로 구성
- 비선형 변환을 생성하는 ReLu (Rectified Linear unit) 함수를 도입하면 더 깊은 층을 쌓을 수 있다는 것을 발견
- 3x3 필터 도입 ( AlexNet 에서는 11x11 필터 사용, 훈련할 매개 변수의 수를 줄이면서 11x11 필터 만큼의 패턴을 인지할 수 있음을 확인 )
- 2014년 ImageNet Challenge 7.3%의 오류율
GoogLeNet ( Inception V1, Inception Module, 2014)
- 같은 해 개발한 Inception Module을 적용
- 한번의 연산에 하나의 필터 적용시켰던 기존의 CNN과 다르게 한번의 연산에 여러개의 필터를 적용시키는 방법
- 신경 망 안에 또 다른 신경망이 있는 Inception Architecture
- 같은 물체일지라도 서로 다른 비율로 존재할 경우 한 종류의 필터를 사용하는 것이 효율적이지 않을 수 있다.

- 9개의 인셉션 모듈을 포함하여, 22 개의 층으로 구성 ( 아래 그림에서 파란색 상자가 연산 층 )
- 각 모듈은 1x1, 3x3, 5x5 Conv. layers와 3x3 max-pool layer로 구성

- 2014 ImageNet Challenge 에서 6.7% 의 오류율
- VGG-16보다 낮은 오류율, 또한 낮은 용량
- VGG-16 은 F.C. layers를 3개나 사용하였으나, GoogLeNet의 경우 Global Average Pooling (G.A.P) 를 사용한 결과
- GAP : 전 층에서 산출된 Feature map들을 각각 평균내어 1차원 벡터로 Pooling ( 연산 x )
- 이후 레이블에 보다 쉽게 접근하기 위해 F.C. layer가 한 개 추가되긴 함.
(https://ctkim.tistory.com/entry/GoogLeNet 참조)
Inception V2 (2015)
- convolution factorization (시작 모듈의 매개변수 수 감소)
- 5x5 conv. 적용하면 25번 연산하는 반에 3x3 conv.를 두번 적용시키면 18번 연산을 통해 5x5와 같은 결과를 얻으면서도 더 적은 매개변수를 사용 가능
- NxN conv.를 1xN 과 Nx1 로 쪼개면, 마찬가지로 매개변수 갯수는 확 주는데 결과는 비슷할 수 있겠다.
- Grid 줄이기
- Conv - Pool (연산량이 늘어남) v.s. Pool - Conv (정보손실이 발생함) => Conv 와 Pool도 병렬로 처리하는건?
- 2012 년 ImageNet Challenge 5.6% 오류율


ResNet (Residual Learning, 2015)
- Residual Learning
- 깊이를 보다 더 많이 증가시키고자 하였으나 오히려 오류율이 증가
- 과적합이 아니라 매우 깊은 모델에 대한 최적화의 어려움 문제 때문.
- Identity Mapping 을 추가함으로써 매개변수를 추가하지 않고도 최적화를 용이하게 함
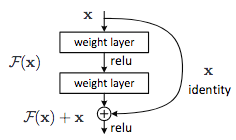
- 152개의 Conv. layer, 3x3 필터로 구성된 2 개 레이어의 블록별 잔차 학습
- 2012 ImageNet Challenge 에서 4.49% 의 오류율
- 2015 ImageNet Challenge 에서 3.57% 의 오류율, 우승

Inception V4 (Inception-ResNet, 2016)
- Inception Network 에 Residual Connection 을 도입
- Inception 연산 후 1x1 Conv. 적용하여 필터를 늘림 (차원 보상 효과)
- 수렴의 속도가 빨라짐, 정확도의 개선이 의미있게 상승하지는 않음.

SENet (Squeeze-and-Excitation Module, 2017)
- 채널 간의 가중치를 계산하여 성능을 끌어올린 모델

- SE Block
- Squeeze : 각 채널을 1차원으로 만듬.
- HxWxC 크기의 피쳐맵을 Global Pooling을 통해 1x1xC 로 압축
- Excitation : 벡터를 정규화 하여 가중치 부여
- FC (C/r 채널) - ReLU - FC (C 채널) - Sigmoid ( Bottle neck 구조 )
- 피쳐맵에 가중치 부여
- Squeeze : 각 채널을 1차원으로 만듬.
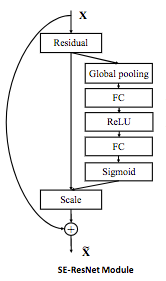
- 2017 ImageNet Challenge 2.25% 오류율, 우승
NAS(Neural Architecture Search, 2017)
- hidden layer는 몇개나 만들지, layer 당 filter는 몇 개를 쓸 것인지, filter의 사이즈, padding, stride, 언제 pooling을 할 등 desigin decision에 대해 자동화하여 주어진 task에 맞는 네트워크 구조를 편리하고 빠르게 탐색하는 방법론을 연구하는 분야
- Recurrent Neural Network의 Cell을 자체 아키텍처를 학습하기 위한 강화학습으로 사용.
- NASNet : CIFRA-10 데이터 세트를 가지고 NAS를 사용해 학습한 아키텍처 블록으로 모델 생성
- ImageNet 2012 Challenge에서 3.8% 의 상위 5 오차율 달성
PNAS (Progressive Neural Architecture Search, 2017)
- 사용 가능한 함수와 조합 연산자 수 감소
- 강화학습 부분 제거
- 단일 기능으로 간단한 구조를 구성하는 것으로 시작하여 최대 블록수에 도달할 때 까지 학습의 최고 점수 기록 및 다른 구조와 함께 쌓는 과정 반복
- 훈련시간은 5배로 줄이면서 NASNet 모델과 동일한 성능 달성

정리

번역한 사이트 :
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-image-classification-5fdbca4a05e2
참고한 레퍼런스 :
https://poddeeplearning.readthedocs.io/ko/latest/CNN/Inception.v4/
https://ctkim.tistory.com/entry/GoogLeNet
https://deep-learning-study.tistory.com/539
https://ahn1340.github.io/neural%20architecture%20search/2021/04/26/NAS.html
'DL' 카테고리의 다른 글
| U-Net 실습2 - 네트워크 구조, Dataloader, Transform 구현 (0) | 2023.07.06 |
|---|---|
| U-Net 실습1 - DataSet 다운 및 Split, Docker에서 GUI 설정하기 (0) | 2023.07.06 |
| [YOLO; You Only Look Once] Unified, Real-Time Object Detection (0) | 2023.06.29 |
| 순환 신경망 실습 (0) | 2023.06.25 |
| [Transformer] Attention is all you need (보완 예정) (0) | 2023.06.22 |