
- groupby
df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=True).count()
df_train[['Pclass','Survived']].groupby(['Pclass']) 를 하면 groupby 객체가 하나 만들어집니다.
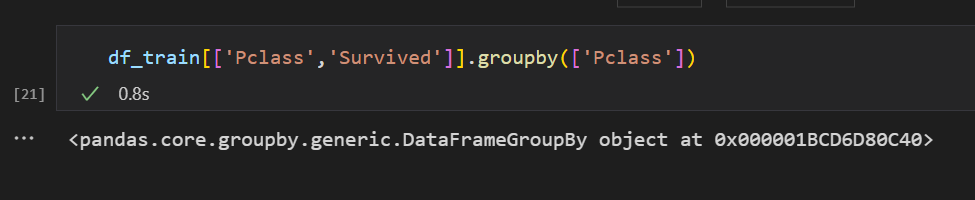
groupby는 수많은 메소드를 가지고 있는데
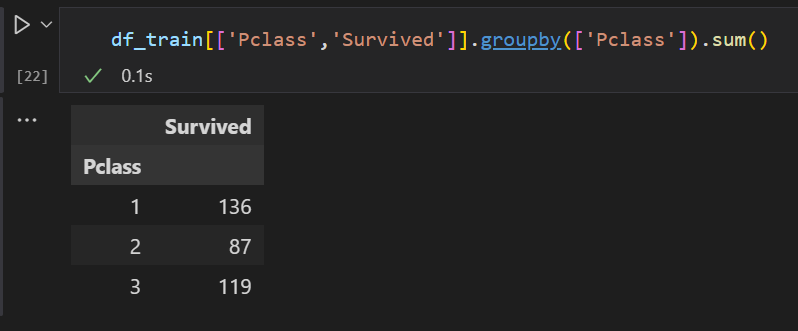
가령, sum ( 그룹바이 별로 합친거 )
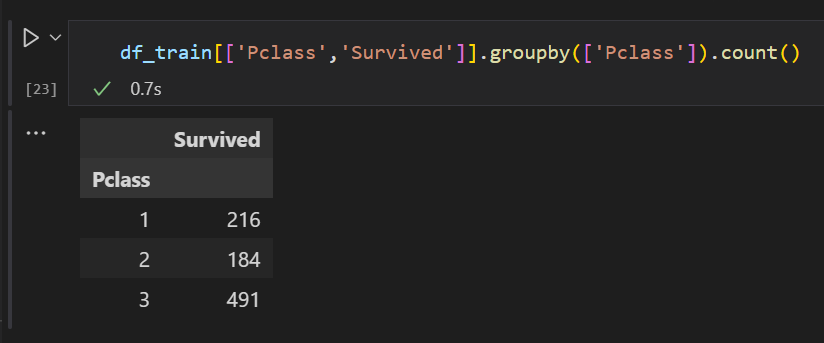
count( 그룹바이 별 갯수 )
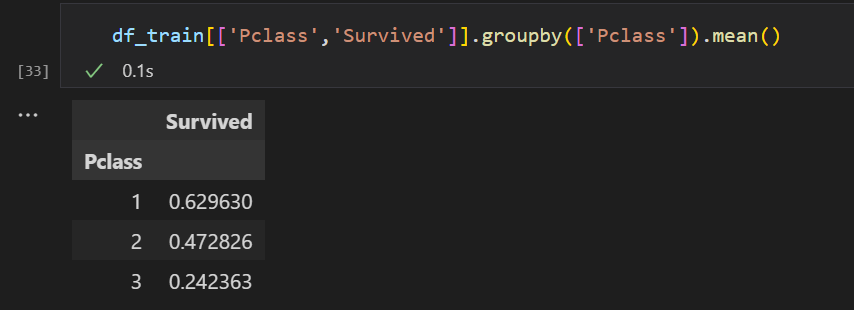
mean( 그룹바이 별 평균 ), 자료가 바이너리 일 때는 결국 % 가 되겠다.
as_index는 앞에 인덱스를 Pclass로 둘지 (True) 아니면 그냥 별도로 하나 만들지 (False) 입니다.
as_index = True를 해야 그림을 그릴 때 편하겠다.
- crosstab
pd.crosstab(df_train['Pclass'], df_train['Survived'], margins=True)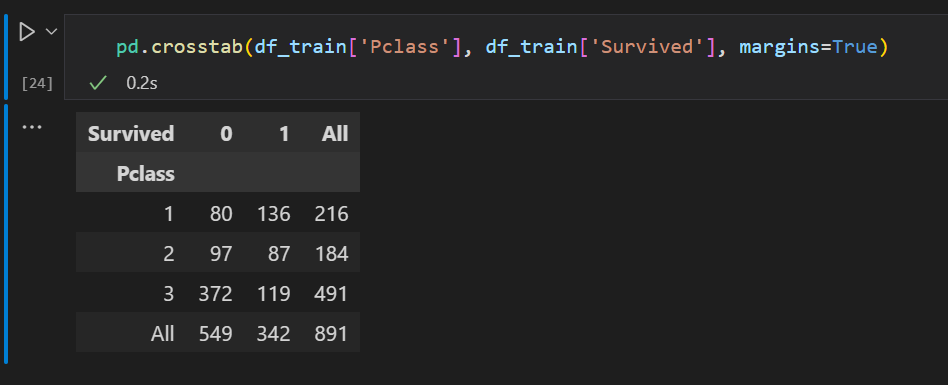
위의 그룹 바이에서 보면 sum 에서 Pclass 가 136 이었던 이유를 알 수 있게 되었습니다.
0*80 + 1*136 = 136 이니 그렇게 된 것이었네요
margins는 총계 표시 관련 옵션입니다.
다음과 같이 스타일도 변경해줄 수 있습니다.
pd.crosstab(df_train['Pclass'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')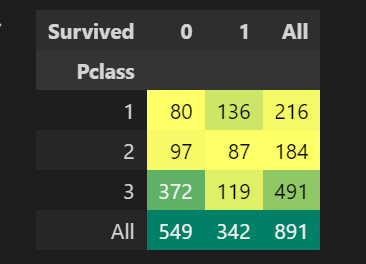
df_train[['Pclass','Survived']].groupby(
['Pclass'],
as_index=True
).mean().sort_values(by='Survived', ascending=False).plot.bar()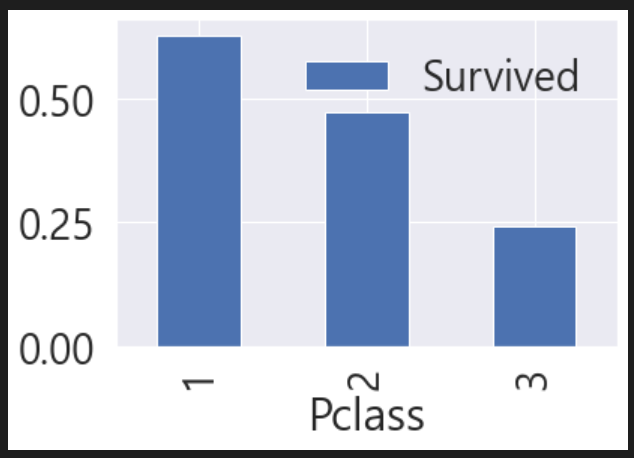
as_index를 True로 했기 때문에 survived에 대한 그림 하나만 그릴 수 있었다.
출처
이유한님, "타이타닉 튜토리얼 1 - Exploratory data analysis, visualization, machine learning", Kaggle-KR(블로그), 2018년 6월 28일, https://kaggle-kr.tistory.com/17?category=868316
'EDA' 카테고리의 다른 글
| [SNS] Seaborn 의 factorplot을 이용해보자. (0) | 2022.07.19 |
|---|---|
| [SNS] seaborn을 가지고 만드는 막대차트 (0) | 2022.07.19 |
| [plt] subplots 만들어서 파이차트와 countplot 차트 넣기 (0) | 2022.07.19 |
| [MissingNo] 결측값 시각화해서 보기 (0) | 2022.07.19 |
| [Pandas] NaN 값 한눈에 보기 (0) | 2022.07.19 |