https://arxiv.org/html/2508.11116v1#bib.bib1
근래 Rag 에 관심이 생겼는데
마침 재밌어 보이는 논문이 나와서 리뷰하게 되었습니다.
초록을 먼저 보고 어떤 내용인지 대략적으로 파악했고,
Idea를 대략적으로 이해한 다음,
Experiment를 보고 이게 실제 효과가 있는 Method인지 확인했고,
이후 구현 부분을 보았습니다.
구현은 논문에서 나온 바와 마찬가지로 Formula 위주로 정리하였습니다.
구체적인 방법이 안궁금하시면 Result 까지만 보고 슥 넘기면 되겠습니다.
앞으로 논문 읽을 때 이렇게 읽고 정리해보면 어떨까 싶은데..
혹시 더 나은 방법이나 피드백 있으시면 조언 부탁드립니다.
초록
- AS-IS
- 논문 초록 수집 및 인덱스 구성 - 디테일한 검색 어려움.
- BE-TO
- 오프라인 계층적 인덱싱 + 온라인 적응형 검색으로 구성된 Paper Register 제안
Idea

논문 검색할 때, 단순히 초록에 나온 내용 가지고만 검색하지말고,
계층적 인덱싱 트리(오프라인) + 뷰 인식 기반 적응적 검색(온라인) 을 해서 검색 성능 높여보자
Result

용어 설명
- Dataset
- LitSearch
- gpt-4 사용하여 논문 인용문(쿼리로) 다시 작성한 597개 논문 검색 쿼리
ex) 생성된 요약의 일관성 평가에 대한 연구는 어디서 찾을 수 있나요?
- gpt-4 사용하여 논문 인용문(쿼리로) 다시 작성한 597개 논문 검색 쿼리
- Flexible-grained Search
- 머신러닝 분야 논문 4200편 코퍼스 형태로 수집, 오프라인 계층적 인덱싱 진행. (테스트, 훈련 데이터 5 대 5로 진행)
- Qwen3-32B를 사용하여 레지스터 각 내용과 관련된 원문 논문 텍스트 검색, 이렇게 뽑은 텍스트를 다시 Qwen3-32B를 사용하여 쿼리 생성. (일반 단위 F.g.Search-1, 미세 단위 F.g.Search-2, 매우 미세 단위 F.g.Search-3)
- 테스트 / 학습 / 검증 데이터셋 구성
- 5644개 테스트 데이터 {q, p}
- 13824개 훈련 데이터, 695개 검증 데이터 {q, v, p}
- LitSearch
- Baselines
- Direct Matching
- Title, Abstract, Total Paper
- 직접 인용하여 코퍼스 인덱스 구축 후, 질의어와 매칭
- Title, Abstract, Total Paper
- Query-paraphrasing Methods (Qwen3-32B)
- Rewriting (Ma et al. 2023)
- LLM 이용하여 쿼리 재작성
- HyDE (Gao et al. 2023)
- LLM 이용하여 입력 쿼리 기반 가짜 문서 생성 이를 이용해 실제 문서 검색
- CSQE (Lei et al. 2024)
- 여러 문서 검색 후, LLM 사용하여 처음 검색된 문서 기반 원래 쿼리를 확장.
- Rewriting (Ma et al. 2023)
- Paper-splitting Methods
- 원본 논문을 여러 개의 짧은 부분으로 분할한 후, 질의와 각 짧은 부분 간의 유사도를 계산
최종적으로 모든 유사도 통합하여 질의와 원본 논문의 전체 유사도를 결정. - 자르는 방식
- Chunk ( 512 토큰 )
- Paragraph ( 문단 단위 청크 )
- 유사도 계산 방식
- Average - 각 부분의 유사도를 평균 내어 사용. (고르게 관련이 있는지.)
- Maximum - 부분 중 가장 높은 유사도를 사용. (쿼리와 가장 관련된 부분이 있는지.)
- 원본 논문을 여러 개의 짧은 부분으로 분할한 후, 질의와 각 짧은 부분 간의 유사도를 계산
- Direct Matching
결과 해석
디테일한 검색 (Flexible-grained) 에서 특히 강점을 보인다.
특히 BM25 기반 검색에서 강점을 보인다.
구현
Task Formula
쿼리와 인덱스를 이용하여, 관련성 있는 논문을 뽑아낸다.
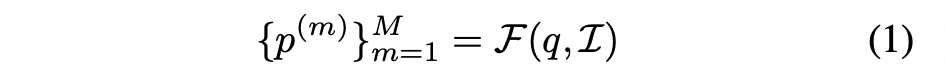
- q: 사용자가 입력하는 쿼리 (검색어)
- 𝒞: 전체 논문 코퍼스(= 데이터베이스)
- ℐ: 코퍼스를 기반으로 만든 인덱스(검색 색인 구조)
- ℱ(q, ℐ): 검색 함수 → 쿼리 q와 인덱스 ℐ를 입력받아,
- {p(m)}m=1…M: 관련 논문 M개를 반환
오프라인 계층적 인덱스
Hierarchical Register Schema
논문을 각 노드로 이루어진 트리 구조로 재 구현하겠다.
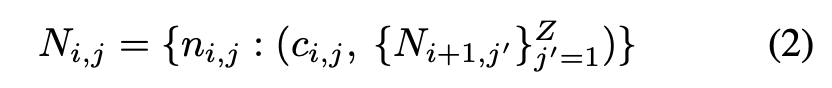
- N_{i,j} : i번째 레벨(layer)의 j번째 정보 노드
- : 노드 이름 (ex: "Method Implementation")
- c_{i,j} : 노드의 내용 (논문에서 해당되는 실제 텍스트)
- {N_{i+1,j'}} : 하위 레벨에 속하는 서브 노드 집합
- Z : 하위 노드 개수
- L : 전체 레벨 수
five types of paper including "algorithm innovation", "benchmark construction", "mechanism exploration", "survey", and "theory proof"
LLM을 사용해 논문의 유형을 자동 분류 → 해당 유형에 맞는 스키마를 할당 → 계층적 인덱스 트리 생성
Fine-grained Content Extracting
LLM한테 노드와 논문 텍스트 전체를 주고, 해당 내용을 찾아서 c에 기록하도록 함.
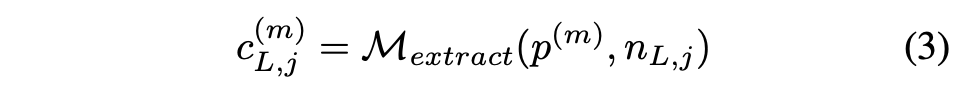
- p^{(m): m번째 논문(paper)
- nL,j: L번째 레벨에서 j번째 정보 노드의 이름 (예: “Training Operation”)
- M_extract: 추출 모듈(extracting module)
- cL,j(m): 실제로 추출된 콘텐츠 (논문에서 해당 노드에 맞는 내용)
Bottom-up Aggregation
하위 노드들을 모아 상위 노드의 요약(c)를 만듭니다.

- ci,j: 논문 의 i번째 레벨, j번째 노드의 내용
- 입력: 바로 아래 레벨(i+1)의 자식 노드들
- M_aggregate: 집계(aggregation) 모듈
하위 노드들을 입력으로 받아서, LLM으로 요약, 압축, 불필요한 디테일을 제거합니다. ( coarser-grained content )
이걸 최상위 레벨 까지 반복합니다.

- I_h: 전체 논문 코퍼스 C에 대한 계층적 인덱스 트리
- ci,j(m): m번째 논문에서 i번째 레벨, j번째 노드의 내용
- M_idx: 인덱싱 모듈 (BM25, DPR 기반)
- I_{i,j}: 인덱스 트리에서 특정 레벨 i, 노드 j에 해당하는 인덱스
모든 논문의 노드 내용을 모아 인덱스를 생성합니다. => 계층적 인덱스 트리 완성.
온라인 적응형 검색
View Identifying
쿼리를 입력하면, 뷰 인식기가 뷰 후보 top-K 개 반환 합니다.

- : 입력 쿼리
- v_k: k번째로 식별된 뷰(view)
- 후보 집합: 계층적 레지스터 스키마의 모든 노드 경로(node path)
- M_identify: 뷰 인식기 (view recognizer)
- 출력: 쿼리에 해당할 가능성이 높은 개의 뷰 후보
뷰 인식기는 소규모 언어 모델을 학습하여 사용 합니다. ( 쿼리 -> 뷰 매핑 )
Beam Search 전략을 통해 여러 개 후보 경로를 동시에 탐색하면서 Top-K 뷰를 출력합니다.
ex) "training operation"
>> "method implementation > training operation"
>> "experiment" > "training setup"
View-based Matching

- I_h : 전체 계층적 인덱스 트리
- v_k : 뷰 인식기에서 나온 쿼리 관련 Top-K 뷰 후보들
- M_lookup : 인덱스 조회 모듈
- I_k : 각 뷰 v_k에 해당하는 인덱스
뷰 후보들과 계층적 인덱스 트리를 입력으로 받아서, 인덱스 조회를 진행합니다.

- s(q,p(m)): 쿼리 q와 논문 의 최종 유사도 점수
- M_rel : 유사도 계산 모듈 (BM25, DPR)
- c_k : 논문 p(m)의, 뷰 v_k에 해당하는 내용
노드 내용이 쿼리와 맞는지 유사도 점수를 계산합니다.
정리하자면
- 쿼리
- 뷰 인식
- 해당 뷰 인덱스 조회
- 쿼리와 논문 내용 비교하여 유사도 점수 계산
- 가장 높은 점수 뷰 선택 (max pooling)
- top-M 논문 반환
View Recognizer Training
- 0.6B 모델로 뷰 인식기 훈련시키는 과정에 대한 설명
- 빠르게 동작해야하고, 정확해야 합니다.
- SFT + GRPO를 적용합니다.

Training Data
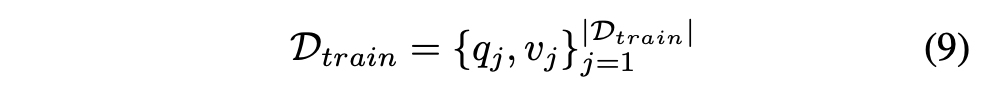
- q_j: 학습 쿼리
- v_j: 해당 쿼리의 정답 뷰(golden view) → 계층적 레지스터 스키마에서 하나의 경로
(예: Abstract → Method → Implementation → Operation)
특정 뷰에 치우치지 않도록 데이터셋을 구성하였다고 합니다.
Supervised Fine-tuning (SFT)
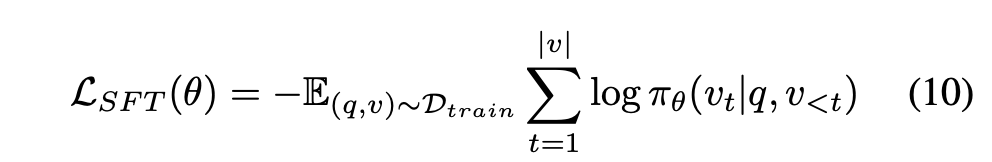
쿼리와 정답 뷰를 가지고 지도학습을 진행합니다.
작은 모델이 최소한 정답 경로를 따라갈 수 있도록 baseline을 학습합니다.
Hierarchical-reward GRPO
강화학습인 Group Relative Policy Optimization을 사용합니다.
완전히 틀린 것과, 어느정도 맞춘것 등을 구별하기 위해 계층적 보상을 주었다고 합니다.
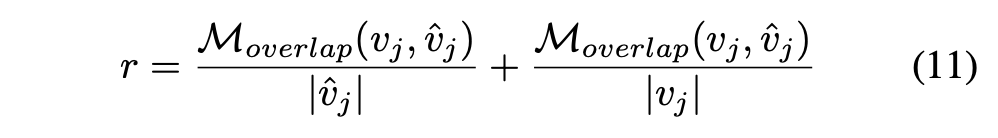
- M_overlap: golden view와 predicted view의 경로 겹치는 정도
- |\hat{v}_j|: 예측 뷰 경로 길이
- |v_j|: 정답 뷰 경로 길이
- 즉, 예측 경로가 정답과 얼마나 겹치는지 비율로 계산 → 가까울수록 더 높은 보상
Precision + Recall 이네요. Precision과 Recall을 동등하게 고려했다라고도 표현할 수 있을 것 같습니다.
- Dice
- 2PR/(P+R)
- 왜 Dice Score로 안했지?
- F1 Score 처럼 둘 다 높아야 점수가 높은 구조는 보상이 희소하기 때문에 모델이 개선되기 어려울 것 같습니다.
- 강화학습에서는 보상이 모델을 어떻게 유도하냐가 중요합니다. 따라서 점진적 개선을 장려한다고 생각하면 될 것 같습니다.
- Jaccard
- PR/(P+R-PR)
- 전체 중 얼마나 겹쳤는지를 보며, Dice Score와 마찬가지로 엄격한 평가 지표 입니다.
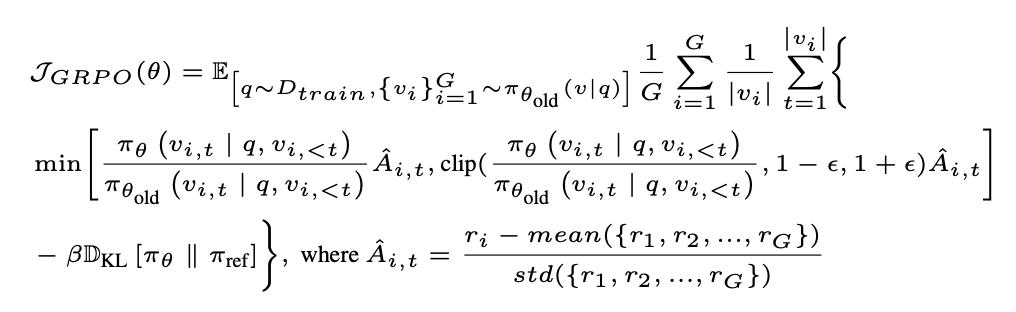
GRPO는 PPO(Proximal Policy Optimization) 변형이고, 위 보상값 r을 활용합니다.
- SFT 모델(πθold)로 초기화
- Beam search로 여러 후보 뷰 {v_i} 샘플
- 각 후보에 대해 hierarchical reward 계산
- 상대 보상(Relative Advantage, \hat{A}_{i,t})을 기반으로 정책 업데이트
- KL divergence (D_{KL}) 항도 포함 → 모델이 너무 벗어나지 않게 제약
Advanced
View Recognizer의 효과와 학습 방법
- 뷰 인식기의 성능이 올라갈수록 PaperRegister의 검색 성능이 같이 향상되었습니다.
- SFT + GRPO를 적용한 0.6B 모델이 Qwen3-32B 보다 정확도와 지연시간이 모두 우수하였습니다.
- SFT만 적용하면, 정확도가 떨어집니다.
- GRPO에서 1/0 보상만 쓰면, 정확도가 낮아집니다.
- SFT + GRPO를 했을 때 성능이 가장 좋았습니다.

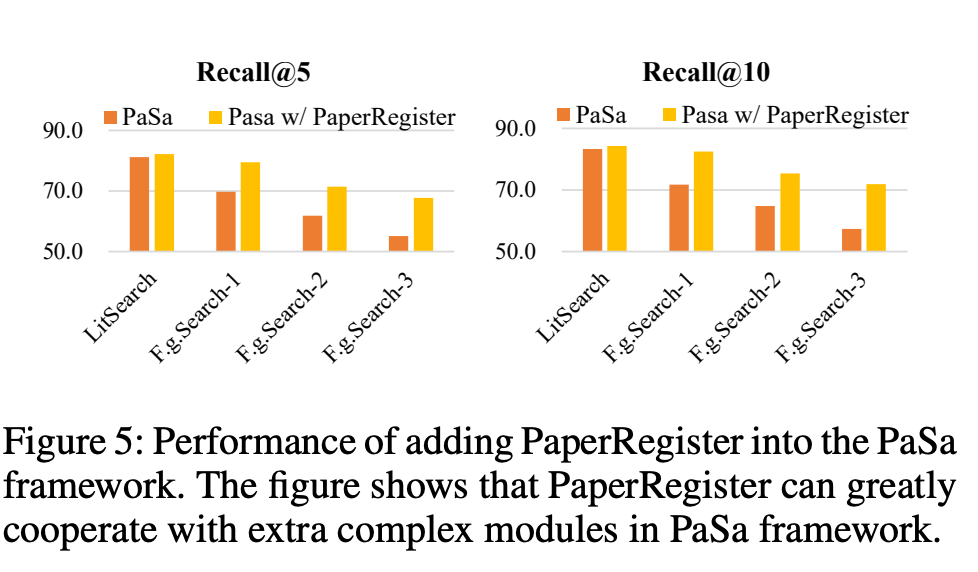
PaSa Framework 와의 호환성
- PaSa (He et al. 2025) : rewriting, retrieval, iteration, filtering 등 모듈이 많은 최신의 복잡한 논문 검색 프레임 워크 입니다.
- PaSa의 원래 retrieval 모듈을 PaperRegister로 교체해봤는데, 성능이 많이 좋아진 것을 확인할 수 있었습니다.
온라인 검색 효율성 분석

속도가 충분히 빠르더라 라는 내용.
재밌었습니다.
뷰 인식기, 오프라인 계층 인덱스 트리 재밌었어요.
'Paper' 카테고리의 다른 글
| MemOS: A Memory OS for AI System (5) | 2025.07.20 |
|---|---|
| An Introduction to Vision-Language Modeling - 논문 리뷰 1 (0) | 2025.03.02 |
| DoLa: Decoding by Contrating Layers Improves Factuality in Large Language Models (2) | 2024.09.04 |
| Transformer to T5 (두 줄 history, 2018 ~ 2019) (0) | 2024.07.18 |