
출처: https://arxiv.org/pdf/2405.17247 - meta 2024.05.27
추천 받은 논문 리스트:
1) https://turingpost.co.kr/p/vision-language-model
2) https://github.com/jingyi0000/VLM_survey
For complete and more technical surveys on VLMs, please refer to Zhang et al. [2024a], Ghosh et al. [2024], Zhou and Shimada [2023], Chen et al. [2023a], Du et al. [2022], Uppal et al. [2022], and Liang et al. [2024].
메타에서 발표한 Introduction to VLM 입니다.
VLM Field에 입문하고자하는 분을 대상으로 하는 논문으로, ( 학생들을 위한 Easy to Understand 라고 합니다. )
VLMs 가 무엇인지, 어떻게 작동하는지, 어떻게 학습시키는지, 어떻게 평가하면 좋을지, 그리고 더 나아가 비디오로는 어떻게 확장시킬 것인지를 다룹니다.
아래는 논문의 내용을 번역 및 제 나름대로 재구성한 글 입니다.
1. Introduction
Llama, ChatGPT 와 같은 LLMs가 출연한 뒤로 이를 Vision에 까지 확장하면 어떨까 하는 시도가 있어왔습니다.
그러나 대부분의 VLM 모델은
1) 공간적 관계를 잘 이해 못하고
2) 숫자를 잘 세지 못하며
3) 속성들을 잘 이해 못하고
4) 순서를 잘 이해 못합니다.
따라서 전혀 상관 없는 결과물이 나타나는, Hallucinate가 발생하기도 하고,
입력 프롬프트를 몇 빼먹기도 합니다.
이를 해결 하기 위해 추가적인 데이터 주석에 의존하는 복잡한 엔지니어링 작업을 필요로 하기도 하고,
상당한 프롬프트 엔지니어링을 요구하기도 합니다.
신뢰할 수 있는 VLM을 개발하는 것은 아직 활발한 연구 과제로 남아있다고 합니다.
그래서..
VLM이 무엇일까요?
2. The Families of VLMs
VLMs를 잘 이해하기 위해 학습 패러다임 별로 분류하여 모델들의 예시를 보도록 하겠습니다.
사실 원래 분류 체계가 있는 상태에서 모델이 만들어진 것이 아니라.
나와있는 모델들을 가지고 임의로 분류하는 것이기 때문에, 실제로는 서로 겹치는 부분도 많고 따라서 엄밀한 분류는 아닙니다.
그러나 분류를 함으로써 VLM에 대해 잘 모르는 연구자들로 하여금 매커니즘을 이해할 수 있는 시야를 줄 수 있다는게 논문 저자의 설명입니다. < 여기가 제 감동 모먼트 >
* 참고로 VLMs 연구들의 설명은 Transformer 기반 [ Vaswani et al., 2017 ] 에 설명이 맞추어져 있습니다.
2.0. Four Categories for Training Paradigms
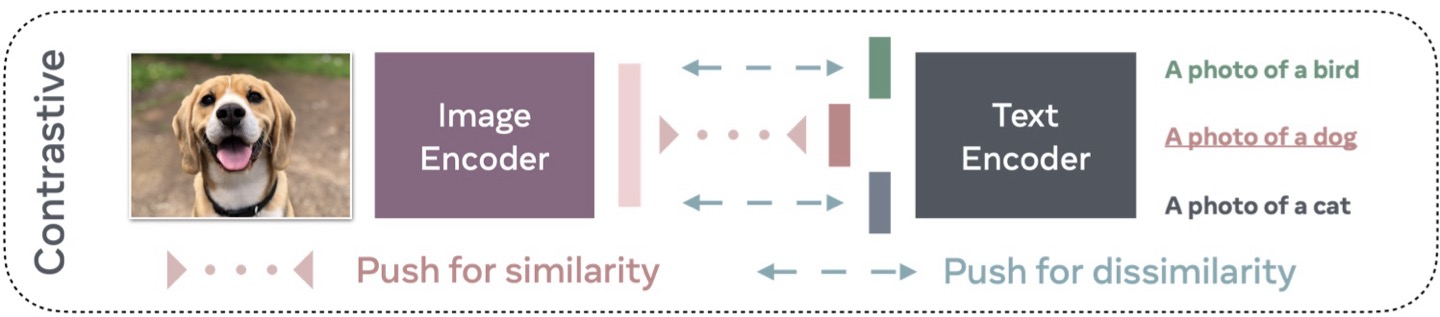
- Contrastive Based
- 긍정적인 예제와 부정적인 예제 쌍을 활용하는 일반적인 전략 입니다.
- VLM에서는 긍정적인 쌍에 대해 유사한 표현을 예측하고, 부정적인 쌍에 대해 서로 다른 표현을 예측하도록 훈련됩니다.
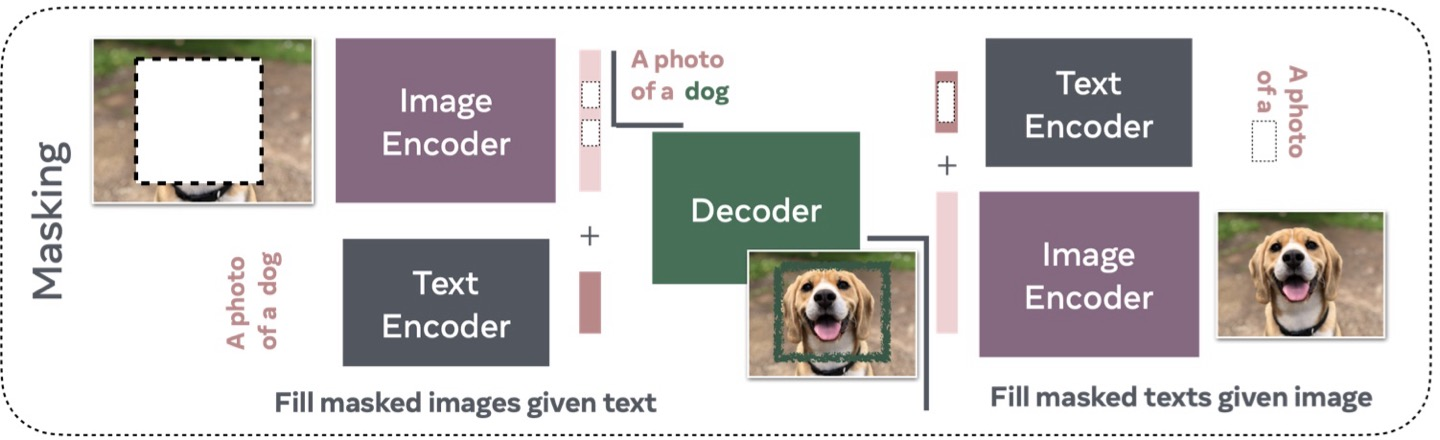
- Masking Based
- 일부 텍스트가 주어졌을 때, 마스킹된 이미지 패치를 복원하는 방식입니다. - Fill masked images given text
- 캡션 내 단어를 마스킹하면, 해당 단어를 복원하도록 훈련할 수도 있습니다. - Fill masked texts given image

- Generative Based
- 대부분의 접근법은 Intermediate Representation이나 Partial Reconstruction을 활용하는 반면, Generative VLM은 전체 이미지를 생성하거나, 매우 긴 캡션을 생성할 수 있도록 훈련 됩니다.
- 이러한 모델 특성상, 훈련 비용이 많이 들 수 있습니다.

- Pretrained Backbones Based
- Llama [Touvron et al., 2023] 와 같은 오픈 소스 LLM을 이용하여 이미지 인코더(마찬가지로 사전 훈련된 모델을 사용할 수 있습니다.)와 LLM 간의 매핑을 학습합니다.
- 계산 비용이 적게 들 수 있습니다.
2.1. Early work on VLMs based on transformers
아주 초창기의 VLMs를 봐보겠습니다.
Transformer의 구조를 기반으로 만들어진 BERT [Delvin et al., 2019]는 그때 당시 엄청난 성능으로 언어 모델들을 흽쓸고 있었습니다. 당연하게도 이를 가지고 Visual Data를 다뤄보려는 시도가 있었습니다.
- visual-BERT[Li et al., 2019] & ViL-BERT[Lu et al., 2019]
- combine text with images tokens.
- 2 Objects
- Masked Modelling: 주어진 입력에서 누락된 부분 예측
- Sentence - Image Prediction: 주어진 캡션이 실제로 이미지 내용 설명하는지 예측
- 다양한 Visual-Language 태스크에서 뛰어난 성능을 보여주었습니다.
- 이는 트랜스포머 모델이 어텐션 메커니즘을 통해 단어와 시각적 단서를 연관 짓는 능력을 학습할 수 있기 때문으로 설명됩니다.
2.2. Contrastive-Based VLMs
대조학습은 Energy-Based Models(EBM) [LeCunet al., 2006] 관점으로 더 잘 설명됩니다.
EBM에서는 매개변수 θ 를 갖는 모델
입력 데이터 x에 대한 에너지 함수 E_ θ(x) 를 고려했을 때,
데이터의 확률은 아래와 같이 볼츠만 분포의 밀도 함수로 설명될 수 있습니다.
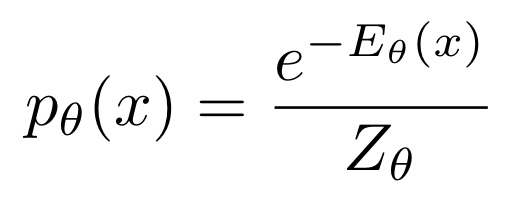
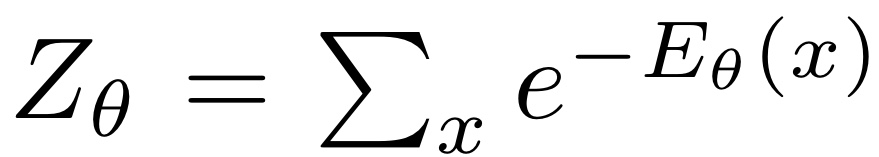
목표 분포 P_D 를 추정하기 위해, 최대 우도 추정을 사용할 수 있습니다.
- 최대 우도 추정
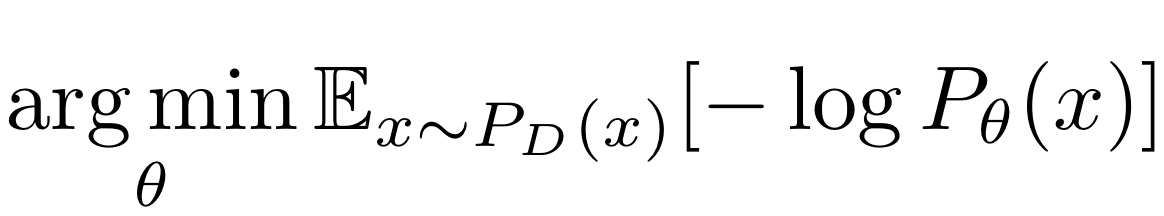
- Gradient
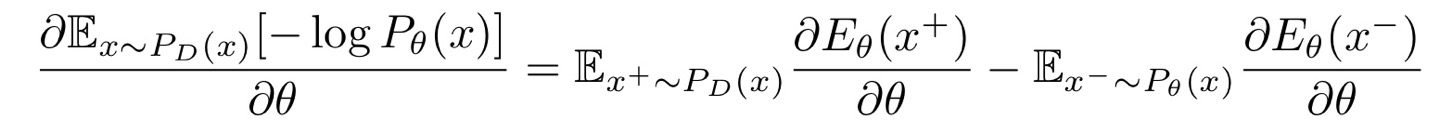
- Gradient 유도 및 항에 대한 의미 정리

* 참고로 정규화에서 사용되는 X는 임의의 변수(모델이 생성 or 샘플링한)이기 때문에 다음과 같이 항의 의미가 나누어지게 됩니다.
이렇게 나온 식에서, 정규화에 사용되는 X의 확률 분포는 말씀드린 것과 같이 모델 분포에서 샘플링한 데이터이기 때문에 이를 계산하기 어렵습니다. 따라서 이를 근사하기 위한 몇 가지 테크닉을 사용하게 됩니다.
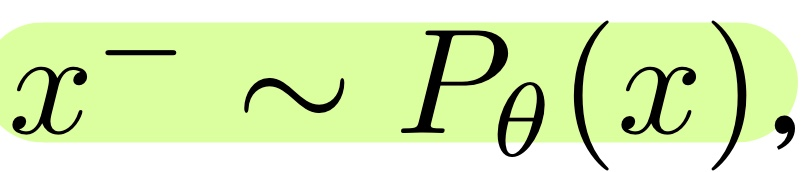
- MCMC (Markov Chain Monte Carlo)
- Iterative Process를 통해 Predicted Energy를 최소화 하는 샘플을 찾는 방식
- Score Matching[Hyvarinen, 2005] & Denosing Score Matching[Vincent, 2011]
- 확률 밀도 함수의 정규화 인자를 제거해버리고, 입력 데이터에 대한 확률 밀도의 경사만 학습하는 방식
- NCE (Noise Contrastive Estimation)[Gutmann and Hyvarinen, 2010]
- 대부분의 자기지도 학습 모델과 최신 VLM이 기반으로 삼는 기법
- 모델 분포에서 부정 예제를 샘플링하는 대신, 노이즈 분포에서 샘플링한 데이터를 사용하여 근사하는 방식
- 아직 왜 잘되는지 이론적으로 정당화되지 않았지만, 최근 SSL 연구(Self-Supervised Learning) 에서 실험적 입증을 보였다고 합니다.[Chen et al., 2020]
NCE framework
원래의 NCE 프레임워크는 이진 분류 문제에서 시작되었습니다.
모델은 실제 데이터 분포에서 나온 샘플에 대해 C = 1 을 예측하고, 노이즈 분포에서 나온 샘플에 대해 C = 0을 예측하도록 학습합니다. ( 노이즈 분포란 이미지나 신호 등에 포함되는 무작위적인 변동을 수학적으로 모델링한 것 입니다. 일반적으로 모델의 임의 출력, 샘플링한 것의 분포에 대해 계산하기 어렵기 때문에, 계산이 용이한 단순한 분포를 사전에 정의하여 사용 합니다. )
NCE 손실 함수는 다음과 같은 크로스 엔트로피로 정의될 수 있습니다.
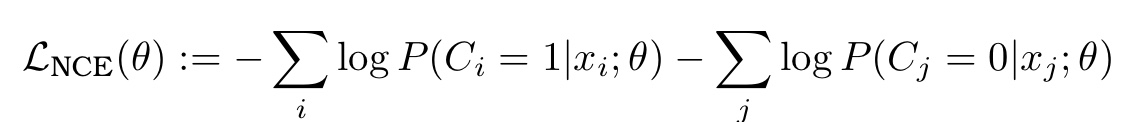
NCE는 모델이 실제 데이터와 노이즈 데이터를 구별하도록 학습시키며, 이 과정에서 모델 분포와 노이즈 분포 사이의 상대적 비율을 추정합니다.( 앞의 항은 실제 데이터에 대한 예측 확률, 뒤의 항은 노이즈 분포에서 온 데이터에 대한 예측 확률 )
* 일반적인 BCE 손실 함수
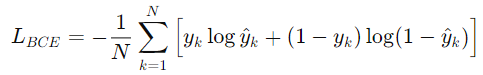
모델이 각 샘플에 대해 올바른 확률 값을 내도록 학습.
NCE 손실 함수에서 뒤의 항만 없으면 BCE 손실 함수인 것입니다.
* Wu et al.[2018] 은 Positive Pair 없이 NCE를 적용하는 비모수적 소프트맥스와 온도 매개변수를 사용한 변형을 제안하였습니다.
* Oor et al. [2018, CPC]는 Positive Pair을 유지한 채, NCE를 적용하는 InfoNCE를 제안하였으며, 이는 아래와 같이 정의 됩니다.
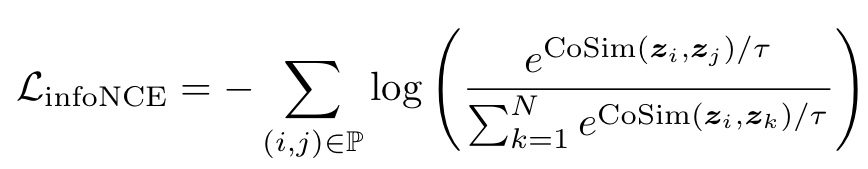
Binary Value를 예측하는 대신, Consine Similarity 와 같은 거리 계산 함수를 사용 합니다.
- InfoNCE loss function 설명
- 소프트맥스를 사용해, 주어진 기준 샘플과 여러 후보 샘플 간의 유사도 점수를 확률 분포로 변환합니다.
( 그리고 거기에 크로스-엔트로피를 적용하여 손실함수를 만듭니다. ) - 기준 샘플과 양성 샘플 간의(Positive Pair) 유사도를 지수 함수로 변환한 값을, 기준 샘플과 모든 후보 샘플(Negative Pair) 간의 지수화 된 유사도 합으로 나눕니다. 이를 통해 Positive Pair의 상대적 유사도가 높아지도록 학습됩니다. (Soft-max)
- 소프트맥스를 사용해, 주어진 기준 샘플과 여러 후보 샘플 간의 유사도 점수를 확률 분포로 변환합니다.
* 참고로온도 매개 변수(타우)는 분포의 날카로움을 조절합니다.
한 때 비전에 강화학습을 녹여내어, 적은 데이터 레이블로 우수한 성능을 달성하여 유명했던 SimCLR에 바로 InfoNCE가 적용되었습니다.
- SimCLR[Chen et al., 2020]
- Positive Pair: 한 이미지와 그에 해당하는 handcrafted data augmented version
( Gray Scale을 적용한 이미지 등 ) - Negative Pair: 한 이미지와 미니배치 내의 다른 모든 이미지
- Positive Pair: 한 이미지와 그에 해당하는 handcrafted data augmented version
그러나 이는 미니배치 크기에 대한 의존성이 주요 제약이 될 수 있습니다.
CLIP
InfoNCE 손실을 활용하는 대표적인 대조 학습 방법 중 하나는 Contrastive Language-Image Pre-traning (CLIP)[Radford et al., 2021] 입니다.
- CLIP
- Positive Pair: 하나의 이미지와 그에 해당하는 캡션 (Ground Truth Caption)
- Negative Pair: 같은 이미지와 미니 배치 내 다른 이미지들을 설명하는 모든 다른 캡션
CLIP의 혁신적인 점은 Vision과 Language를 Shared Representation Space에서 통합하는 모델을 학습한다는 것입니다.
대조 손실 함수를 가지고 무작위로 초기화된 Vision Encoder와 Text Encoder를 학습시켜, 이미지와 이에 해당하는 캡션의 Representation을 유사한 인베딩 벡터에 매핑할 수 있도록 합니다.
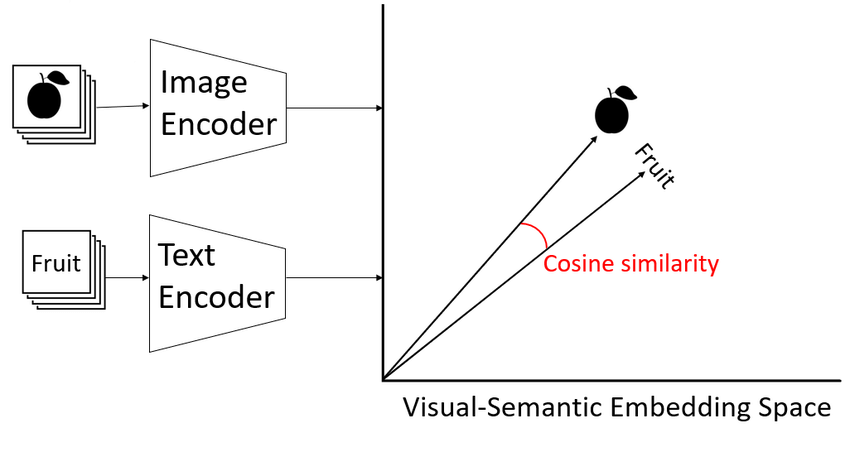
원래의 CLIP 모델은 웹에서 수집한 4억 개의 캡션 - 이미지 쌍을 기반으로 훈련되었으며, 탁월한 zero-shot classification transfer 능력을 보여주었습니다.
특히, ResNet-101 기반 CLIP은 Supervised Learning한 ResNet과 동등한 성능 (Zero-Shot 분류 정확도 76.2%)를 달성했으며, 여러 Robustness benchmark에서 이를 능가했다고 합니다.
* zero-shot classification transfer: 모델이 한 데이터셋에서 학습한 후, 전혀 보지 못한 새로운 데이터셋에서 제로샷 추론을 보일 수 있는 능력
- SigLIP[Zhai et al. 2023b]
- original NCE loss를 사용했다. ( BCE 기반인 )
- mini-batch에서는 CLIP보다 성능이 더 좋다. (InfoNCE의 제약으로 인해)
- Latent language image pretraining(Llip)[Lavoie et al., 2024]
- 하나의 이미지가 여러 방식으로 캡션될 수 있다는 점을 고려
- 특정 캡션을 조건으로 이미지 인코딩을 조정하는 Cross-Attention Module 도입.
- 캡션의 다양성을 반영하면 Expressivity가 증가하며, 결과적으로 zero-shot transfer classification 과 retrieval 성능이 증가한 것으로 확인하였습니다.
2.3 VLMs with masking objectives
마스킹 기법은 딥러닝 연구의 대표적인 테크닉 입니다.
- Masking 용례
- Denosing AutoEncoder의 한 기법 ( 노이즈가 공간적 구조를 띌 때의. )[Vincent et al., 2008]
- Strong Visual Representations을 학습하기 위한 inpainting 전략[Pathak et al. 2016]
- BERT[Devlin et al., 2019]에서는 MLM(Masked Language Modeling)을 사용하여 문장에서 누락된 토큰을 예측하는 방식으로 사용되었습니다.
Masking 기법은 Transformer 구조와 특히 잘 어울리는데, 이는 Input Signal을 Tokenization 하는 작업이 특정 입력 토큰을 무작위로 제거하기에 매우 용이하기 때문입니다.
Vision 쪽 에서는 Representations을 학습하기 위해 MIM(Masked Image Modeling)이 사용되었습니다.
MAE[He et al.2022], I-JEPA[Assran., 2023]
자연스럽게도 Masking 기법을 사용하여 VLM을 학습하려는 시도 또한 있어 왔습니다.
- FLAVA[Singh et al., 2022]
- MaskVLM[Kwon et al, 2023]
FLAVA
트랜스포머 프레임워크를 기반으로 특정 모달리티 처리하도록 설계된 세 가지 핵심 구성 요소로 이루어져 있습니다.
- Image Encoder
- 비전 트랜스포머(Vit, Vision Transformer)[Dosovitskiy et al., 2021]을 활용해 이미지를 작은 패치로 분할한 후, 이를 분류 토큰 ([CLS_I]) 과 함께 Linear Embedding과 Transformer-based Representation 으로 변환합니다.
- Masking 기법을 사용해 학습합니다.
- Text Encoder
- 트랜스포머[Vaswani et al., 2017]을 사용하여 텍스트 입력을 토큰화하고, 이를 문맥에 따라 처리할 수 있도록 벡터로 임베딩하여 Hidden State Vectors와 분류 토큰 ([CLS_T]) 을 출력합니다.
- Masking 기법을 사용해 학습합니다.
- Multimodal Encoder
- 학습된 Linear Projection과 크로스-어텐션 메커니즘을 활용하여 시각 정보와 텍스트 정보를 통합한 분류 토큰 ([CLS_M])을 만들어냅니다.
FLAVA는 다양한 학습 목표를 결합하여 훈련 시켰습니다.
- Multi Modal Masked Modeling
- Uni Modal Masked Modeling
- Contrastive Learning
그리고 무려 7천만 개의 이미지-텍스트 쌍으로 모델을 사전학습하였습니다.
그 결과, 비전, 언어, 멀티모달을 포함하는 35가지 태스크에서 State-Of-Art를 달성하였습니다.
MaskVLM
FLAVA의 한계점은 dVAE[Zhang et al., 2019] 와 같은 사전 학습된 Vision Encoders 를 사용한다는 점 입니다.
Third-Party Model에 대한 의존성을 줄이기 위해 제안된 모델이 바로 MaskVLM[Kwon et al, 2023] 입니다.
(dVAE 와 같은 사전 학습된 모델이 데이터와 학습 방식에 있어서 특정 편향성을 가지고 있다는 뜻으로 짐작해봅니다. Representation에 한계가 있다라는 의미로 들리기도 하네요.)
이 모델은 Pixel Space와 Text Token Space에 직접 마스킹을 적용합니다.
( 가공 전 데이터에서 마스킹을 직접 적용함으로써 Third-Party Model에 대한 의존성을 해소합니다. )
하나의 모달리티로부터 다른 모달리티로 전달되는 정보의 흐름을 활용하는게 바로 키 아이디어라는 것 같은데 해당 내용은 MaskVLM 논문을 읽어봐야 이해할 수 있을 것 같습니다.
내용이 너무 길어져서 끊어가지고 정리해야할 것 같습니다.
이후 글에서는 Generative-Based 와 Pretrained Backbones 라는 VLM 학습 패러다임에 대해 마저 읽어보고
VLM을 어떻게 학습 시키면 좋은지와 Evaluation 방법, 그리고 VLM과 영상물 과의 관련성 등에 대해서는 앞으로의 글들로 마저 읽어보려 합니다.
출처: https://arxiv.org/pdf/2405.17247 - meta 2024.05.27
추천 받은 논문 리스트:
1) https://turingpost.co.kr/p/vision-language-model
2) https://github.com/jingyi0000/VLM_survey
For complete and more technical surveys on VLMs, please refer to Zhang et al. [2024a], Ghosh et al. [2024], Zhou and Shimada [2023], Chen et al. [2023a], Du et al. [2022], Uppal et al. [2022], and Liang et al. [2024].
메타에서 발표한 Introduction to VLM 입니다.
VLM Field에 입문하고자하는 분을 대상으로 하는 논문으로, ( 학생들을 위한 Easy to Understand 라고 합니다. )
VLMs 가 무엇인지, 어떻게 작동하는지, 어떻게 학습시키는지, 어떻게 평가하면 좋을지, 그리고 더 나아가 비디오로는 어떻게 확장시킬 것인지를 다룹니다.
아래는 논문의 내용을 번역 및 제 나름대로 재구성한 글 입니다.
1. Introduction
Llama, ChatGPT 와 같은 LLMs가 출연한 뒤로 이를 Vision에 까지 확장하면 어떨까 하는 시도가 있어왔습니다.
그러나 대부분의 VLM 모델은
1) 공간적 관계를 잘 이해 못하고
2) 숫자를 잘 세지 못하며
3) 속성들을 잘 이해 못하고
4) 순서를 잘 이해 못합니다.
따라서 전혀 상관 없는 결과물이 나타나는, Hallucinate가 발생하기도 하고,
입력 프롬프트를 몇 빼먹기도 합니다.
이를 해결 하기 위해 추가적인 데이터 주석에 의존하는 복잡한 엔지니어링 작업을 필요로 하기도 하고,
상당한 프롬프트 엔지니어링을 요구하기도 합니다.
신뢰할 수 있는 VLM을 개발하는 것은 아직 활발한 연구 과제로 남아있다고 합니다.
그래서..
VLM이 무엇일까요?
2. The Families of VLMs
VLMs를 잘 이해하기 위해 학습 패러다임 별로 분류하여 모델들의 예시를 보도록 하겠습니다.
사실 원래 분류 체계가 있는 상태에서 모델이 만들어진 것이 아니라.
나와있는 모델들을 가지고 임의로 분류하는 것이기 때문에, 실제로는 서로 겹치는 부분도 많고 따라서 엄밀한 분류는 아닙니다.
그러나 분류를 함으로써 VLM에 대해 잘 모르는 연구자들로 하여금 매커니즘을 이해할 수 있는 시야를 줄 수 있다는게 논문 저자의 설명입니다. < 여기가 제 감동 모먼트 >
* 참고로 VLMs 연구들의 설명은 Transformer 기반 [ Vaswani et al., 2017 ] 에 설명이 맞추어져 있습니다.
2.0. Four Categories for Training Paradigms
- Contrastive Based
- 긍정적인 예제와 부정적인 예제 쌍을 활용하는 일반적인 전략 입니다.
- VLM에서는 긍정적인 쌍에 대해 유사한 표현을 예측하고, 부정적인 쌍에 대해 서로 다른 표현을 예측하도록 훈련됩니다.
- Masking Based
- 일부 텍스트가 주어졌을 때, 마스킹된 이미지 패치를 복원하는 방식입니다. - Fill masked images given text
- 캡션 내 단어를 마스킹하면, 해당 단어를 복원하도록 훈련할 수도 있습니다. - Fill masked texts given image
- Generative Based
- 대부분의 접근법은 Intermediate Representation이나 Partial Reconstruction을 활용하는 반면, Generative VLM은 전체 이미지를 생성하거나, 매우 긴 캡션을 생성할 수 있도록 훈련 됩니다.
- 이러한 모델 특성상, 훈련 비용이 많이 들 수 있습니다.
- Pretrained Backbones Based
- Llama [Touvron et al., 2023] 와 같은 오픈 소스 LLM을 이용하여 이미지 인코더(마찬가지로 사전 훈련된 모델을 사용할 수 있습니다.)와 LLM 간의 매핑을 학습합니다.
- 계산 비용이 적게 들 수 있습니다.
2.1. Early work on VLMs based on transformers
아주 초창기의 VLMs를 봐보겠습니다.
Transformer의 구조를 기반으로 만들어진 BERT [Delvin et al., 2019]는 그때 당시 엄청난 성능으로 언어 모델들을 흽쓸고 있었습니다. 당연하게도 이를 가지고 Visual Data를 다뤄보려는 시도가 있었습니다.
- visual-BERT[Li et al., 2019] & ViL-BERT[Lu et al., 2019]
- combine text with images tokens.
- 2 Objects
- Masked Modelling: 주어진 입력에서 누락된 부분 예측
- Sentence - Image Prediction: 주어진 캡션이 실제로 이미지 내용 설명하는지 예측
- 다양한 Visual-Language 태스크에서 뛰어난 성능을 보여주었습니다.
- 이는 트랜스포머 모델이 어텐션 메커니즘을 통해 단어와 시각적 단서를 연관 짓는 능력을 학습할 수 있기 때문으로 설명됩니다.
2.2. Contrastive-Based VLMs
대조학습은 Energy-Based Models(EBM) [LeCunet al., 2006] 관점으로 더 잘 설명됩니다.
EBM에서는 매개변수 θ 를 갖는 모델
입력 데이터 x에 대한 에너지 함수 E_ θ(x) 를 고려했을 때,
데이터의 확률은 아래와 같이 볼츠만 분포의 밀도 함수로 설명될 수 있습니다.
목표 분포 P_D 를 추정하기 위해, 최대 우도 추정을 사용할 수 있습니다.
- 최대 우도 추정
- Gradient
- Gradient 유도 및 항에 대한 의미 정리
* 참고로 정규화에서 사용되는 X는 임의의 변수(모델이 생성 or 샘플링한)이기 때문에 다음과 같이 항의 의미가 나누어지게 됩니다.
이렇게 나온 식에서, 정규화에 사용되는 X의 확률 분포는 말씀드린 것과 같이 모델 분포에서 샘플링한 데이터이기 때문에 이를 계산하기 어렵습니다. 따라서 이를 근사하기 위한 몇 가지 테크닉을 사용하게 됩니다.
- MCMC (Markov Chain Monte Carlo)
- Iterative Process를 통해 Predicted Energy를 최소화 하는 샘플을 찾는 방식
- Score Matching[Hyvarinen, 2005] & Denosing Score Matching[Vincent, 2011]
- 확률 밀도 함수의 정규화 인자를 제거해버리고, 입력 데이터에 대한 확률 밀도의 경사만 학습하는 방식
- NCE (Noise Contrastive Estimation)[Gutmann and Hyvarinen, 2010]
- 대부분의 자기지도 학습 모델과 최신 VLM이 기반으로 삼는 기법
- 모델 분포에서 부정 예제를 샘플링하는 대신, 노이즈 분포에서 샘플링한 데이터를 사용하여 근사하는 방식
- 아직 왜 잘되는지 이론적으로 정당화되지 않았지만, 최근 SSL 연구(Self-Supervised Learning) 에서 실험적 입증을 보였다고 합니다.[Chen et al., 2020]
NCE framework
원래의 NCE 프레임워크는 이진 분류 문제에서 시작되었습니다.
모델은 실제 데이터 분포에서 나온 샘플에 대해 C = 1 을 예측하고, 노이즈 분포에서 나온 샘플에 대해 C = 0을 예측하도록 학습합니다. ( 노이즈 분포란 이미지나 신호 등에 포함되는 무작위적인 변동을 수학적으로 모델링한 것 입니다. 일반적으로 모델의 임의 출력, 샘플링한 것의 분포에 대해 계산하기 어렵기 때문에, 계산이 용이한 단순한 분포를 사전에 정의하여 사용 합니다. )
NCE 손실 함수는 다음과 같은 크로스 엔트로피로 정의될 수 있습니다.
NCE는 모델이 실제 데이터와 노이즈 데이터를 구별하도록 학습시키며, 이 과정에서 모델 분포와 노이즈 분포 사이의 상대적 비율을 추정합니다.( 앞의 항은 실제 데이터에 대한 예측 확률, 뒤의 항은 노이즈 분포에서 온 데이터에 대한 예측 확률 )
* 일반적인 BCE 손실 함수
모델이 각 샘플에 대해 올바른 확률 값을 내도록 학습.
NCE 손실 함수에서 뒤의 항만 없으면 BCE 손실 함수인 것입니다.
* Wu et al.[2018] 은 Positive Pair 없이 NCE를 적용하는 비모수적 소프트맥스와 온도 매개변수를 사용한 변형을 제안하였습니다.
* Oor et al. [2018, CPC]는 Positive Pair을 유지한 채, NCE를 적용하는 InfoNCE를 제안하였으며, 이는 아래와 같이 정의 됩니다.
Binary Value를 예측하는 대신, Consine Similarity 와 같은 거리 계산 함수를 사용 합니다.
- InfoNCE loss function 설명
- 소프트맥스를 사용해, 주어진 기준 샘플과 여러 후보 샘플 간의 유사도 점수를 확률 분포로 변환합니다.
( 그리고 거기에 크로스-엔트로피를 적용하여 손실함수를 만듭니다. ) - 기준 샘플과 양성 샘플 간의(Positive Pair) 유사도를 지수 함수로 변환한 값을, 기준 샘플과 모든 후보 샘플(Negative Pair) 간의 지수화 된 유사도 합으로 나눕니다. 이를 통해 Positive Pair의 상대적 유사도가 높아지도록 학습됩니다. (Soft-max)
- 소프트맥스를 사용해, 주어진 기준 샘플과 여러 후보 샘플 간의 유사도 점수를 확률 분포로 변환합니다.
* 참고로온도 매개 변수(타우)는 분포의 날카로움을 조절합니다.
한 때 비전에 강화학습을 녹여내어, 적은 데이터 레이블로 우수한 성능을 달성하여 유명했던 SimCLR에 바로 InfoNCE가 적용되었습니다.
- SimCLR[Chen et al., 2020]
- Positive Pair: 한 이미지와 그에 해당하는 handcrafted data augmented version
( Gray Scale을 적용한 이미지 등 ) - Negative Pair: 한 이미지와 미니배치 내의 다른 모든 이미지
- Positive Pair: 한 이미지와 그에 해당하는 handcrafted data augmented version
그러나 이는 미니배치 크기에 대한 의존성이 주요 제약이 될 수 있습니다.
CLIP
InfoNCE 손실을 활용하는 대표적인 대조 학습 방법 중 하나는 Contrastive Language-Image Pre-traning (CLIP)[Radford et al., 2021] 입니다.
- CLIP
- Positive Pair: 하나의 이미지와 그에 해당하는 캡션 (Ground Truth Caption)
- Negative Pair: 같은 이미지와 미니 배치 내 다른 이미지들을 설명하는 모든 다른 캡션
CLIP의 혁신적인 점은 Vision과 Language를 Shared Representation Space에서 통합하는 모델을 학습한다는 것입니다.
대조 손실 함수를 가지고 무작위로 초기화된 Vision Encoder와 Text Encoder를 학습시켜, 이미지와 이에 해당하는 캡션의 Representation을 유사한 인베딩 벡터에 매핑할 수 있도록 합니다.
원래의 CLIP 모델은 웹에서 수집한 4억 개의 캡션 - 이미지 쌍을 기반으로 훈련되었으며, 탁월한 zero-shot classification transfer 능력을 보여주었습니다.
특히, ResNet-101 기반 CLIP은 Supervised Learning한 ResNet과 동등한 성능 (Zero-Shot 분류 정확도 76.2%)를 달성했으며, 여러 Robustness benchmark에서 이를 능가했다고 합니다.
* zero-shot classification transfer: 모델이 한 데이터셋에서 학습한 후, 전혀 보지 못한 새로운 데이터셋에서 제로샷 추론을 보일 수 있는 능력
- SigLIP[Zhai et al. 2023b]
- original NCE loss를 사용했다. ( BCE 기반인 )
- mini-batch에서는 CLIP보다 성능이 더 좋다. (InfoNCE의 제약으로 인해)
- Latent language image pretraining(Llip)[Lavoie et al., 2024]
- 하나의 이미지가 여러 방식으로 캡션될 수 있다는 점을 고려
- 특정 캡션을 조건으로 이미지 인코딩을 조정하는 Cross-Attention Module 도입.
- 캡션의 다양성을 반영하면 Expressivity가 증가하며, 결과적으로 zero-shot transfer classification 과 retrieval 성능이 증가한 것으로 확인하였습니다.
2.3 VLMs with masking objectives
마스킹 기법은 딥러닝 연구의 대표적인 테크닉 입니다.
- Masking 용례
- Denosing AutoEncoder의 한 기법 ( 노이즈가 공간적 구조를 띌 때의. )[Vincent et al., 2008]
- Strong Visual Representations을 학습하기 위한 inpainting 전략[Pathak et al. 2016]
- BERT[Devlin et al., 2019]에서는 MLM(Masked Language Modeling)을 사용하여 문장에서 누락된 토큰을 예측하는 방식으로 사용되었습니다.
Masking 기법은 Transformer 구조와 특히 잘 어울리는데, 이는 Input Signal을 Tokenization 하는 작업이 특정 입력 토큰을 무작위로 제거하기에 매우 용이하기 때문입니다.
Vision 쪽 에서는 Representations을 학습하기 위해 MIM(Masked Image Modeling)이 사용되었습니다.
MAE[He et al.2022], I-JEPA[Assran., 2023]
자연스럽게도 Masking 기법을 사용하여 VLM을 학습하려는 시도 또한 있어 왔습니다.
- FLAVA[Singh et al., 2022]
- MaskVLM[Kwon et al, 2023]
FLAVA
트랜스포머 프레임워크를 기반으로 특정 모달리티 처리하도록 설계된 세 가지 핵심 구성 요소로 이루어져 있습니다.
- Image Encoder
- 비전 트랜스포머(Vit, Vision Transformer)[Dosovitskiy et al., 2021]을 활용해 이미지를 작은 패치로 분할한 후, 이를 분류 토큰 ([CLS_I]) 과 함께 Linear Embedding과 Transformer-based Representation 으로 변환합니다.
- Masking 기법을 사용해 학습합니다.
- Text Encoder
- 트랜스포머[Vaswani et al., 2017]을 사용하여 텍스트 입력을 토큰화하고, 이를 문맥에 따라 처리할 수 있도록 벡터로 임베딩하여 Hidden State Vectors와 분류 토큰 ([CLS_T]) 을 출력합니다.
- Masking 기법을 사용해 학습합니다.
- Multimodal Encoder
- 학습된 Linear Projection과 크로스-어텐션 메커니즘을 활용하여 시각 정보와 텍스트 정보를 통합한 분류 토큰 ([CLS_M])을 만들어냅니다.
FLAVA는 다양한 학습 목표를 결합하여 훈련 시켰습니다.
- Multi Modal Masked Modeling
- Uni Modal Masked Modeling
- Contrastive Learning
그리고 무려 7천만 개의 이미지-텍스트 쌍으로 모델을 사전학습하였습니다.
그 결과, 비전, 언어, 멀티모달을 포함하는 35가지 태스크에서 State-Of-Art를 달성하였습니다.
MaskVLM
FLAVA의 한계점은 dVAE[Zhang et al., 2019] 와 같은 사전 학습된 Vision Encoders 를 사용한다는 점 입니다.
Third-Party Model에 대한 의존성을 줄이기 위해 제안된 모델이 바로 MaskVLM[Kwon et al, 2023] 입니다.
(dVAE 와 같은 사전 학습된 모델이 데이터와 학습 방식에 있어서 특정 편향성을 가지고 있다는 뜻으로 짐작해봅니다. Representation에 한계가 있다라는 의미로 들리기도 하네요.)
이 모델은 Pixel Space와 Text Token Space에 직접 마스킹을 적용합니다.
( 가공 전 데이터에서 마스킹을 직접 적용함으로써 Third-Party Model에 대한 의존성을 해소합니다. )
하나의 모달리티로부터 다른 모달리티로 전달되는 정보의 흐름을 활용하는게 바로 키 아이디어라는 것 같은데 해당 내용은 MaskVLM 논문을 읽어봐야 이해할 수 있을 것 같습니다.
내용이 너무 길어져서 끊어가지고 정리해야할 것 같습니다.
이후 글에서는 Generative-Based 와 Pretrained Backbones 라는 VLM 학습 패러다임에 대해 마저 읽어보고
VLM을 어떻게 학습 시키면 좋은지와 Evaluation 방법, 그리고 VLM과 영상물 과의 관련성 등에 대해서는 앞으로의 글들로 마저 읽어보려 합니다.