
MemTensor- 2025.07.08
장기 문맥 추론, 지속적인 개인화, 지식 일관성 확보
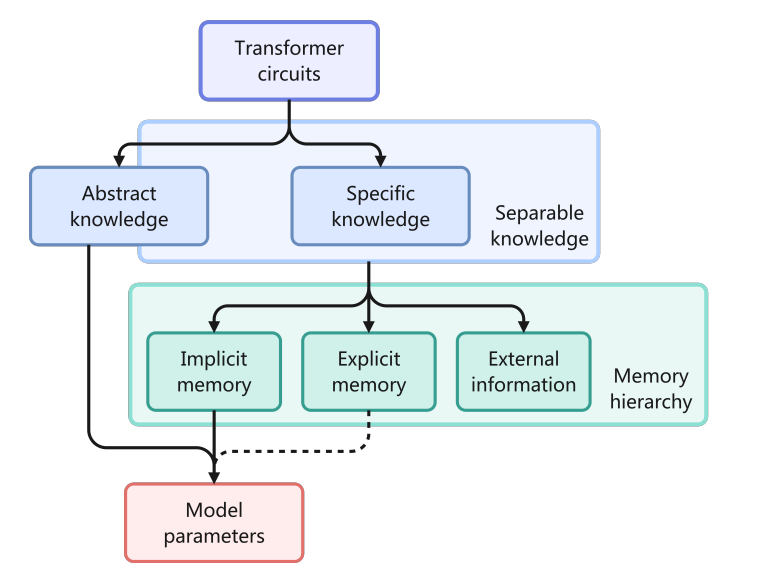
기존 LLM은 모든 지식을 파라미터(모델 내부 값)으로 저장하거나, 잠깐 쓰고 마는 짧은 컨택스트 (Context Window)에 의존합니다.
이를 보강하기 위해, 인터넷 또는 외부 DB에서 정보를 검색해 모델에 넣어주지만, 검색한 내용이 LLM 내 축적되지 않습니다.
최근 연구에 따르면, 파라미터 메모리와 외부 검색 사이에 "명시적 메모리 계층"을 추가하면 특정 지식을 따로 보관했다가 필요할 때만 꺼내 쓰므로 비용(메모리/계산량)을 줄일 수 있다고 합니다.
Hongkang Yang, Zehao Lin, Wenjin Wang, Hao Wu, Zhiyu Li, Bo Tang, Wenqiang Wei, Jinbo Wang, Zeyun Tang, Shichao Song, Chenyang Xi, Yu Yu, Kai Chen, Feiyu Xiong, Linpeng Tang, and Weinan E. Memory3 : Language modeling with explicit memory. Journal of Machine Learning, 3(3):300–346, January 2024
종합적으로 관리하는 시스템이 없다면, 정보가 시간에 따라 흩어지고, 다양한 종류의 지식(최근 대화, 오래된 기억, 새로운 정보 등)이 섞여 있기 때문에 이를 "종합적으로" 관리하는 시스템이 필요합니다.
따라서 본 논문은 "MemOS"를 제안합니다.
- MemOS
- 메모리를 관리 가능한 시스템 자원으로 취급하는 메모리 운영 체제 (Always-On 패러다임)
- 평문, 활성화 기반, 파라미터 수준의 메모리를 통합적으로 표현·스케줄링·진화시켜 비용 효율적인 저장 및 검색
- 대규모 다원적 정보를 효율적으로 관리하고 문맥에 따라 동적으로 메모리를 스케줄링
- 작업 메모리·장기 저장소·콜드 아카이브로 이루어진 계층적 메모리 구조 필요, 최신성·접근 빈도·중요도에 따라 관리
- 여러 사용자·에이전트 간 메모리를 공유하려면 범위 지정, 권한 제어, 이동·재사용 가능한 표현도 필수 (효율성, 장기적 지속성)
- MemCube
- 기본 단위
- 메모리 콘텐츠와 출처, 버전 관리 같은 메타데이터를 함께 캡슐화
- 시간에 따라 조합·이동·융합 용이
- 메모리 유형 간 유연한 전환을 지원
- 검색 기반 학습과 파라미터 기반 학습을 연결
미래 에이전트는 언제 메모리를 검색하거나, 상호작용을 요약해 재사용 규칙으로 만들거나, 선호도를 추상화하거나, 문맥 간 지식을 전이할지 스스로 결정할 수 있어야합니다.
모델이 자체 메모리 아키텍처·전략을 설계·형성하는 책임을 져야 합니다.
그러나 현재 인프라는 이를 지원하지 못합니다.
LLM + RAG
생명주기 추적, 버전 관리, 권한 기반 스케줄링 같은 핵심 메모리 관리 기능이 없어 장기·적응형 지식 시스템을 지원하기 어렵습니다.
그 결과, 모델은 다중 회차 대화·계획·개인화 작업에서 여전히 단기 기억 행동을 보이며, 행동 일관성이나 장기 적응에 한계를 드러냅니다.
LLM 내부에 명시적·계층적 메모리 표현이 없기 때문입니다.
시스템 관점에서 볼 때, 파라미터 메모리도 RAG도 메모리를 스케줄·진화 가능한 시스템 자원으로 취급하지 않습니다. 이 구조적 공백은 LLM이 지속적·협업적 지능형 에이전트로 발전하는 데 핵심 병목으로 남아 있습니다.
과제나 대화가 길어질수록, 모델은 여러 턴‧단계를 거쳐도 지시(instruction)와 상태(state)의 일관성을 유지해야 합니다. 그러나
Long-range Dependency Modeling
제한된 컨텍스트 윈도우
**어텐션 연산이 O(n²)**라 계산 비용이 크다.
장기 과제에서 사용자 지시가 모델 행동과 분리돼버린다
Adapting to Knowledge Evolution
현실 세계의 지식은 법규 개정, 과학 발견, 시사 등 끊임없이 변합니다. 하지만 정적 파라미터는 이를 제때 반영하지 못합니다. RAG는 동적 검색을 허용하지만, 버전 관리·출처 추적·시간 인식이 없는 무상태 패치일 뿐입니다. 그 결과, 옛 규정과 새 규정을 동시에 인용하면서도 조정하지 못하고, 오래된 사실을 폐기하거나 신뢰도를 우선순위화하거나 지식 변화를 추적하지 못해 장기 일관성이 무너집니다.
Personalization and Multi-role Support
LLM은 사용자·역할·작업 간 지속 ‘기억 흔적’(memory trace)이 없습니다. 세션이 시작될 때마다 초기화되어 누적된 선호나 스타일을 무시하죠. ChatGPT, Claude처럼 메모리 기능을 도입한 서비스도 있지만, 용량 제한·불안정한 접근·불투명한 업데이트·편집 불가 등의 문제가 남아 있습니다. 현 시스템은 수동 기록 위주라, 구조적 제어가 필요한 장기 개인화 시나리오에 맞지 않습니다.
Cross-platform Memory Migration and Ecosystem Diversity
LLM이 웹·모바일·엔터프라이즈 등 다종 엔드포인트로 확장되면서, 사용자 메모리(프로필·작업 기록·선호)는 컨텍스트를 가로질러 지속돼야 합니다. 하지만 대부분의 시스템은 메모리를 특정 인스턴스 안에 가둬 ‘메모리 섬’을 형성
ChatGPT에서 구상한 아이디어가 Cursor로 이어지지 않아, 사용자가 문맥을 다시 구축해야 합니다.
속성을 해치고 메모리 재사용을 막습니다. 더 나아가 중앙집중 vs. 분산 구조의 문제도 있습니다. 독점 플랫폼은 피드백 루프로 이득을 보지만, 분산 모델은 정체 위험이 있습니다. 메모리 이식성·재사용성이 진화 효율과 생태계 다양성의 균형을 잡는 열쇠입니다.
시간과 공간에 흩어진 정보를 일관되게 관리·조정할 능력의 부재
단일 모듈의 문제가 아니라, 메모리를 조직하고 운용할 시스템 수준 기제가 없기 때문
현대 LLM은 파라미터 저장소와 외부 검색 사이에 중간 계층이 없어, 메모리 생명주기를 관리하거나 지식 진화를 통합하거나 행동 연속성을 유지하기 어렵습니다. RAG는 외부 정보를 불러오지만, 통합 구조와 연산적 의미가 없어 장기·제어 가능한 지식 활용을 지원하지 못합니다.
따라서 미래형 언어 지능 시스템을 구축하려면 메모리를 시스템 자원으로 보고 명시적으로 모델링·스케줄링해야 합니다. 전통적 OS가 CPU·RAM·디스크·I/O를 수명 주기 전반에 걸쳐 관리하듯, 대규모 모델에서의 메모리는 암시적 파라미터 또는 일시적 검색 결과에 머물러 스케줄도 추적도 통합도 불가능합니다. 단순히 “캐시를 더 붙이자”거나 “검색 모듈을 달자”가 아니라, 시스템적 관점에서 메모리의 운영 논리와 자원 관리를 재정의해야 합니다.
---
대규모 언어 모델(LLM)의 메모리 기능에 대한 연구는 일반적으로 다음의 네 가지 주요 단계를 거쳐 발전해 왔습니다:
- 정의 및 탐색 단계: 다양한 관점에서 LLM 메모리 시스템을 분류하고 분석하며, 실제 환경에 적용 가능한 최적화 메커니즘을 식별하는 데 중점을 둔 초기 연구 단계입니다.
- 인간 유사 메모리 개발 단계: LLM과 인간의 메모리 간 격차로 인해 복잡한 과제에서 발생하는 성능 문제를 해결하기 위해 인지적으로 영감을 받은 다양한 형태의 메모리 메커니즘을 도입합니다.
- 도구 기반 메모리 관리 단계: 삽입, 삭제, 수정 등 기본적인 기능을 갖춘 모듈형 인터페이스가 등장하지만, 기존 메모리 구조 내에서의 제한적 운용에 머무릅니다.
- 체계적 메모리 거버넌스 단계 (MemOS가 지향하는 목표): 메모리 리소스를 구조적으로 진화시키고 추상화하며 안전하게 제어할 수 있는 시스템 수준의 메모리 관리 체계로 나아갑니다.
---
Stage 1. 메모리 분류
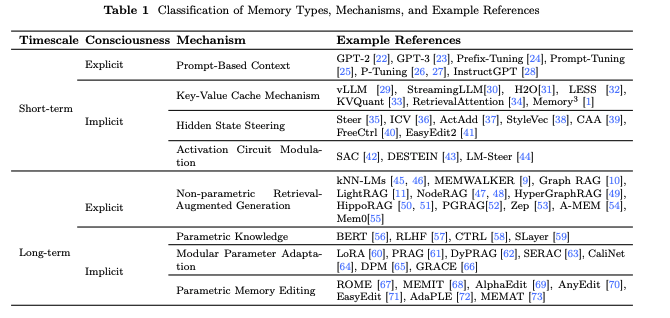
- 선행 연구
선행 연구
- Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions, May 2025. arXiv:2505.00675 [cs].
- 파라미터 메모리
- 비구조적 컨텍스트 메모리
- 구조적 컨텍스트 메모리
- From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs, April 2025. arXiv:2504.15965 [cs].
- Object (개인 v.s. 시스템)
- Form (Parametric v.s. Non-Parametric)
- Temporal Aspects (단기 v.s. 장기)
- Cognitive Memory in Large Language Models, April 2025. arXiv:2504.02441 [cs].
- Based On
- 파라미터 기반
- 키-값 캐시 기반
- 히든 스테이트 기반
- 텍스트 기반
- Retention Duration
- 감각 메모리
- 단기 메모리
- 장기 메모리
- Based On
- 주요 분류
- 암시적(implicit): 파라미터, 키-값 캐시, 히든 스테이트
- 명시적(explicit): 텍스트나 컨텍스트 기반 정보 저장
- 시간에 따른 분류
- 감각 메모리: 인식되지 않는 극히 짧은 시간의 정보 흔적 (단기 메모리에 통합 스케줄링과 처리의 일관성 유지)
- 단기 메모리
- 장기 메모리
암시적 메모리
- Long Term: 직접 표현되지는 않지만, 언어 생성, 지식 표현, 일반화에 지속적인 영향
- Training
- CTRL: A Conditional Transformer Language Model for Controllable Generation, September 2019. (제어 코드로, 컨텍스트 정보 포함 시키도록 학습)
- Memory & Reasoning Fine-tuning: 출력 결과를 메모리와 추론으로 분리하여 추론 성능을 향상
- SLayer: 모델 내부의 메모리 관련 레이어를 식별해 국소적으로 파인튜닝함으로써 특정 지식 표현 강화
- Titans: 온라인 메타 모델을 도입해 학습 중 정보 유지 또는 망각 여부를 동적으로 판단하여 분포 변화에 강인한 메모리 구조 형성(Dynamic Memory Mechanism)
- Adapter
- LoRA: 저랭크 어댑터를 삽입해 원본 파라미터를 건드리지 않고 효율적으로 새로운 지식을 내재화.
- PRAG: 특정 문서나 작업에 대해 학습된 LoRA 어댑터를 ‘메모리 유닛’처럼 다루며 필요 시 병합.
- DyPRAG: 입력 문서를 LoRA 파라미터로 직접 매핑하는 생성기 구조를 사용하여 명시적 메모리 저장 비용을 절감.
- Editing
- Locate-then-edit intuitive methods: 인과 추적을 통해 지식 위치를 파악한 뒤 직접 편집.
- Meta-Learning-Based Methods: 하이퍼네트워크로 파라미터 변화를 직접 예측.
- Adapter-based editing strategies: LLM Backbone을 유지하면서, 세분화된 제어 가능성 확보
- Training
- Short Term: 어텐션 분포와 AutoRegressive Generation 에 의한 행동 전략
- KV-cache: 이전에 처리한 토큰들의 key-value 표현을 저장하여, 오토리그레시브 생성 중에도 과거의 메모리에 지속적으로 접근
- LESS와 KVQuant: low-rank compression과 양자화(quantization)
- StreamingLLM과 H2O: 어텐션 패턴에 따라 덜 중요한 KV 쌍을 동적으로 제거
- retrieval-based memory activation: 캐시 내용에 선택적 접근
- vLLM: 가상 메모리 스타일의 페이지 캐싱(PagedAttention)을 사용함으로써 중복 저장을 줄이고 KV 접근성을 개선
- Hidden State
- steering vectors method: 이 벡터들은 의미적으로 상반된 입력 쌍의 활성값 차이를 계산해 얻어지며, 의미적으로 방향성을 가지는 제어 신호를 형성. 다른 입력의 중간 활성값에 주입하면 모델 아키텍처를 바꾸지 않고도 생성 결과를 특정 의미 방향으로 이끌 수 있습니다.
- Self-Detoxifying, ActAdd, ICV, StyleVec, CAA: 비지도(unsupervised) 대조적(contrastive) 접근을 사용. 의미는 비슷하지만 속성은 반대인 입력 쌍(예: 감정, 태도, 정중함 등)을 만들어 hidden state 차이를 추출하고 steering vector를 생성함으로써 자동화되고 가벼운 신호 도출이 가능하게 합니다. 조정 제어의 적용성을 높이고, 진입 장벽도 낮춥니다.
- ACT, ITI, InferAligner: 환각(hallucination) 완화, 사실성 일관성 향상에 활용.
- IFS: 텍스트 형식, 문장 길이 등, 저수준 생성 특징까지 제어하는 데 확장, hidden state 개입이 추상 의미뿐 아니라 구조적 행동 조절에도 효과적임을 시사
- KV-cache: 이전에 처리한 토큰들의 key-value 표현을 저장하여, 오토리그레시브 생성 중에도 과거의 메모리에 지속적으로 접근
명시적 메모리
- Long Term: 외부의 Non-parametric Knowlege와 지속적인 관계 유지
- 검색-생성 방식
- BM25, Dense Passage Retrieval(DPR), hybrid retrieval과 같은 오프더셸프(off-the-shelf) 검색기
- NPLM (Non-parametic language models)
- kNN-LMs: linear fusion of neural language models
- 메모리 구조 자체의 향상
- 트리 기반
- 그래프 기반
- 검색-생성 방식
- Short Term: 정적인 설정에서 동적인 상호작용
- 학습 가능한 연속 벡터를 활용한 파라미터화된 프롬프트 기법
- 고급 지시문 추종 모델
- InstructGPT류의 지시문 튜닝 패러다임
Stage 2. Human-like Memory
- HippoRAG: 초기 연구, "중요한 기억은 해마가, 세부 기억은 신피질이" 처럼 역할 분담 흉내냄 - but AI 가 더 효율적
- PGRAG: 독서 중 필기하는 인간 해동을 모방해, 명시적 장기 기억으로 마인드맵을 자동 생성
- Second-Me: 인간 유사 기억 행동 중심의 다단계 아키텍처를 제안하며, 경험 중심의 개인화 검색을 강조
- L0: 완전성을 위해 원시 데이터를 저장
- L1: 구조화된 자연어로 조직과 검색성을 향상
- L2: 파라미터 튜닝을 통해 사용자 취향을 내재화하여 인간과 유사한 연상적 추론
- AutoGen: 다중 에이전트 프레임워크 (인간 집단 협업 시뮬레이션)
Stage 3. 도구 기반 메모리 관리
- 지식을 명시적으로 조작하는 방향( INSERT, MODIFY, DELETE, ... )
- Semantic Behavior을 동적으로 업데이트
- EasyEdit: 초기 접근법 - 모델 파라미터와 hidden state 조작
- Mem0: 외부 메모리 모듈 도입, 대화 메모리를 그래프 구조로 만드는 후속 연구
- Ltta: 동적 메모리 접근을 위한 함수형 페이징 방식 도입
Stage 4. 메모리 거버넌스
- MemOS, 본 논문에서 제안하는 메모리 운영체제
- 메모리 단위를 1급 자원(first-class resource)으로 취급
- 운영체제 설계 원리를 기반으로 스케줄링, 계층화, API 추상화, 권한 관리, 예외 처리 등 포괄적 거버넌스 메커니즘을 도입
- MemScheduler, Memory Layering, Memory Governance
MemOS

PayLoad In MemCube
- Plaintext Memory (평문 메모리)
- 외부에서 동적으로 불러오는 지식 모듈 (예: 검색된 문서, 구조화된 그래프, 프롬프트 템플릿 등)
- 수정·추적·저장이 자유로우며, 파라미터/컨텍스트 윈도우 한계를 뛰어넘어, 빠른 지식 업데이트, 과제 맞춤화, 사용자 개인화 등에 매우 유리
- MemCube 단위로 관리(라이프사이클, 접근 정책, 버전 추적)
- 그래프 구조/멀티모달, 상황별 지문(contextual fingerprint), 타임스탬프 기반 관리 등 지원
- 자주 쓰이는 평문은 Activation Memory로 변환될 수 있고, 위계적 그래프(과제-개념-사실 경로)로 구조화되어 효율적 스케줄링 및 장기 진화를 지원
- 중복 제거, 충돌 감지, 버전 관리, 망각 정책 등도 내장
- 특히 사실 중심, 개인화, 다중 에이전트 협업에 필수
- 추론 중 만들어지는 KV캐시 등 중간 상태
- MemOS는 이 메모리의 지연 로딩, 선택적 동결, 우선순위 기반 조정 지원
- 자주 등장하는 패턴은 저지연 ‘즉시 메모리 경로’로 캐시화
- 자주 쓰이는 전략적 행동(스티어링 벡터, 템플릿 등)도 영속 메모리로 추상화 가능
- 대화, 코드 보조, 런타임 안전 관리 등 실시간 맥락 유지에 필수
- 예: 의료 에이전트에서 환자 정보, 진단 루틴, 상식 등을 캐시로 저장해 빠르게 검색
- 모델의 고정 가중치에 저장된 지식과 능력
- 일반적·심층적 의미 표현의 기본, zero-shot 추론/QA/생성의 토대
- MemOS는 미세조정(LoRA, 어댑터 등)을 통한 모듈형 기능 강화 지원
- 도메인 지식을 파라미터 블록(플러그인)으로 증류·적재
- 업데이트 비용, 커스터마이즈 한계, 해석력 부족 등의 단점 보완 위해 평문/활성화 메모리와 연동
- 자주 쓰이는 평문은 파라미터로 증류 가능
- 파라미터가 오래되거나 불일치하면 평문 메모리로 회수
- 법률/재무/기술/요약 등 역량 중심 에이전트에 적합
MetaData In MemCube

Descriptive Identifiers (기술 식별자):
- 각 메모리 블록의 정체성, 분류, 조직을 정의
- 타임스탬프, 생성/최종수정 시점
- 원천(추론, 사용자, 검색, 파라미터 조정 등)
- 의미 타입(프롬프트, 사실, 선호 등)
Governance Attributes (거버넌스 속성):
- 접근 제어, 수명정책(TTL, decay), 우선순위, 준수·추적성
- 메모리의 안정성·투명성·책임성 보장
Behavioral Usage Indicators (행동 사용 지표):
- 실시간 추론 중 메모리 활용 패턴(빈도, 최신성 등)
- 핫/콜드 데이터 판별, 스케줄링 조정
- 타입 간 변환(평문→활성화, 평문/활성화→파라미터 등)
- 상황별 지문(Contextual Fingerprint), 버전체인 관리, 가치 중심 스케줄링, 롤백 등 지원
- 자율적으로 가치 평가·진화·변환이 가능한 ‘지능형’ 메모리 단위로 진화


- 메모리 인터페이스 계층
- Memory API 세트
- Provenance API
- Update API
- LogQuery API
- 검색→증강→업데이트→아카이브 파이프라인 지원 (MemLifecycle 모듈)
- 메모리 단위의 조회, 기록, 갱신, 전송, 합성(조합) 등을 지원
- Memory API 세트
- 메모리 운영 계층
- MemOperator: 태그 시스템, 의미 인덱스, 그래프 기반 토폴로지 등을 구축해 이질적인 메모리와 맥락을 연결, 효율적 검색과 적응 지원
- 기호(symbolic)·의미(semantic) 검색 혼합
- 파이프라인 결합 및 캐싱 전략
- 과제 정렬 라우팅
- MemScheduler: 과제 의도와 맥락에 따라 적절한 메모리 타입(예: 평문, 활성화, 파라미터)을 선택하고, 호출 순서와 통합 전략을 동적으로 계획하여 저지연과 과제 적합성을 최적화
- MemLifecycle: 각 메모리 단위의 라이프사이클(생성, 활성화, 만료, 회수)을 추적해 자원의 통제성과 신선도를 보장
- MemOperator: 태그 시스템, 의미 인덱스, 그래프 기반 토폴로지 등을 구축해 이질적인 메모리와 맥락을 연결, 효율적 검색과 적응 지원
- 메모리 인프라 계층
- MemGovernance는 접근 제어, 보존 정책, 감사 로그, 민감 데이터 처리 등 거버넌스를 집행합니다.
- MemVault는 사용자별, 도메인 지식별, 공유 파이프라인별 등 다양한 메모리 저장소를 관리하고 표준화된 접근 인터페이스를 제공합니다.
- MemLoader와 MemDumper는 메모리 임포트/익스포트, 플랫폼 간 동기화를 지원합니다.
- MemStore는 여러 에이전트 간 개방형 메모리 공유를 위한 퍼블리시-서브스크라이브(pub/sub) 메커니즘을 제공합니다.