

가중치 초기값을 0으로 해버리면 안되나요?

$$ \frac{\partial f }{ \partial x} = \frac {\partial f} {\partial g} \frac{\partial g} {\partial x} $$
$$ \frac{\partial g}{\partial x} = w = 0 $$
가중치 초기화를 0으로 해버리면, 위 식에서와 같이 결국 x 앞단의 모든 값들에 대해 기울기가 0으로 전파되면서 학습이 일어나지 않게 된다.
가중치 초기값을 상수값으로 해버리면 안되나요?
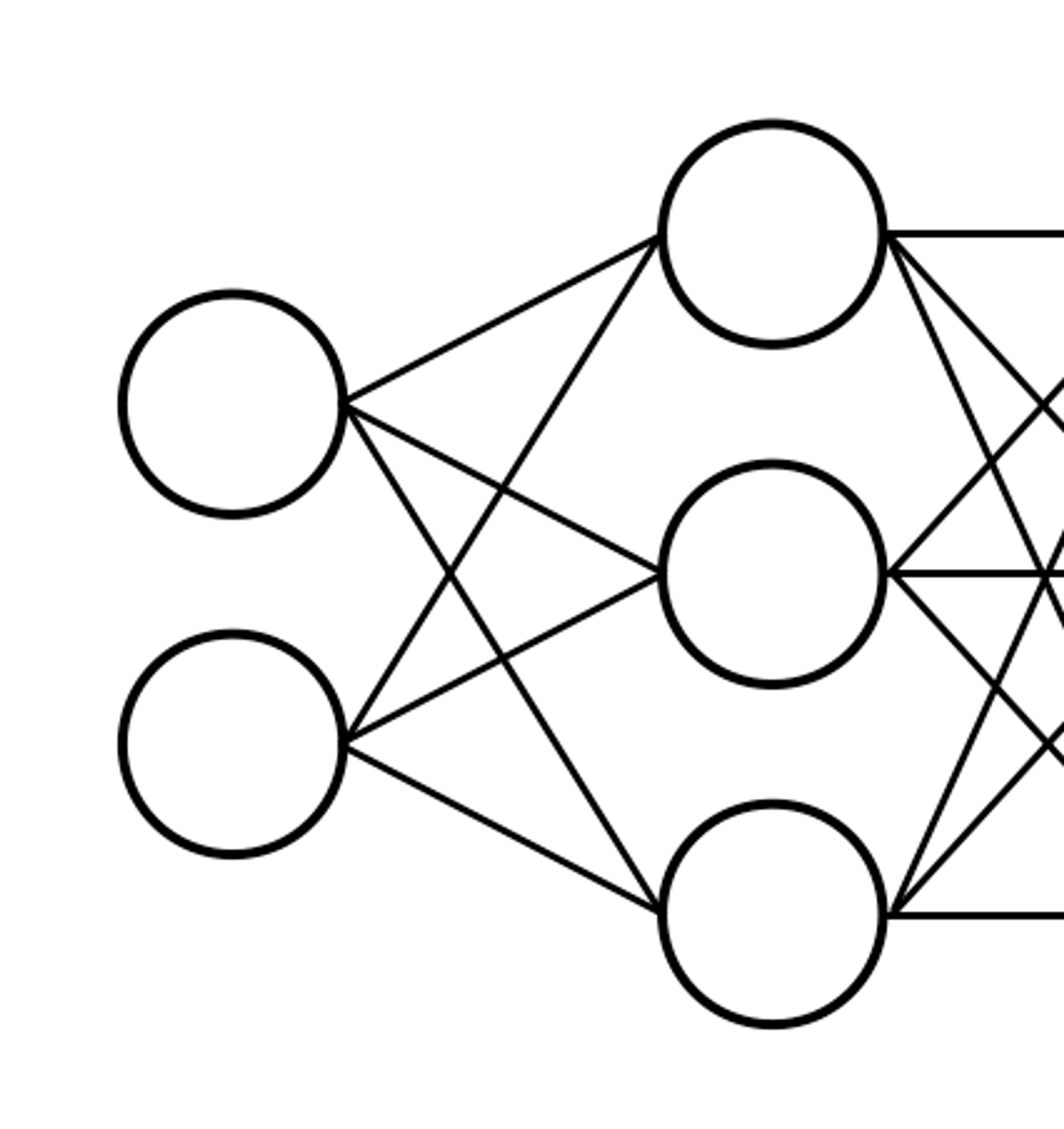
$$ h = input_1 w_1 + input_2 w_2 = W ( input_1 + input_2) $$
$$ h = h_1 = h_2 = h_3 $$
$$ \frac {\partial f}{\partial h} \frac {\partial h}{\partial w_1} = \frac {\partial f}{\partial h} \frac {\partial h}{\partial w_2} = \frac {\partial f}{\partial h} \frac{\partial h}{\partial w_3} $$
모든 노드에 Feature가 대칭적으로, 똑같은 값이 전파되면서 학습이 제대로 이루어지지 않는다.
따라서 난수로 가중치를 초기화함으로써 대칭을 파괴해야한다.
Redundancy로 보는 해석도 있어서 첨한다.
가중치 상수 값이라는것은, 같은 선형 지역을 탐색하겠다는 것이므로,
당연히 탐색이 제대로 이루어지지 않을 것이다.
그럼 Random Initialization 했을 때 문제점은 없을까요?
가중치가 매우 낮은 값으로 초기화 될 경우, 기울기 소실 문제가 발생할 수 있고,
가중치가 매우 높은 값으로 초기화 될 경우, 기울기 폭발 문제가 발생할 수 있는 문제가 있습니다.
따라서 네트워크에 맞는 적절한 가중치 초기화 기법을 사용하여 학습이 원활하게 진행될 수 있도록 하여야 합니다.
Xavier Glorot Initialization 에 대해 설명해주세요.
- Xavier Normal Initialization
$$ W \sim N(0, Var(W)) $$
$$ Var(W) = \sqrt \frac{2}{n_{in} + n_{out}} $$
- Xavier Uniform Initialization
$$ W \sim U(-\sqrt\frac{6}{n_{in}+n_{out}}, + \sqrt\frac{6}{n_{in}+n_{out}} ) $$
Sigmoid, Tanh 계열의 활성화 함수에서 각 레이어에서 나오는 출력 값의 분산이 너무 커지면, 포화 영역으로 값이 밀려나게 되면서 기울기 소실 현상이 발생할 수 있습니다.
(값이 양 끝단으로 밀려나게 되면, 기울기가 점근선에 가까워지게 됩니다.)
Xavier Initialization은 레이어로 전달되는 정보의 분산이 일정하도록 Weight를 초기화하여 이를 극복할 수 있습니다.
Kaiming He initialization 에 대해 설명해주세요.
- He Normal Initiaization
$$ W \sim N(0, Var(W)) $$
$$ Var(W) = \sqrt \frac {2}{n_{in}} $$
- He Uniform Initialization
$$ W \sim U(- \sqrt \frac {6}{n_{in}} , +\sqrt \frac {6}{n_{in}})$$
Relu 활성화 함수가 대중적으로 사용되게 되면서, Relu 함수에 맞는 초기화 방법도 나오게 됐는데, 그게 바로 He Initialization 입니다.
활성화 함수 Relu를 사용할 때, Xavier 초기화를 사용하게 되면, 음수 구간에서 노드가 꺼지기 때문에 데이터의 분산이 점점 작아지게 됩니다.
He 초기화에서는 이에 대해 가중치 분산 값을 키워, 레이어로 전달되는 정보의 분산이 일정할 수 있도록 하였습니다.
Bias는 어떻게 초기화하나요?
Bias는 일반적으로 0으로 초기화한다고 합니다.
아래 글에 Bias를 왜 0으로 초기화해도 되는지에 대한 답안이 나와있는데요,
"가중치 난수 초기화로 선형 독립성이 어느정도 보장된다면 Bias는 0으로 해도 전혀 문제 없다." 정도로 저는 해석하였습니다. 만약 그렇다면 모델이 Zero 부터 학습할 수 있도록 하는 것도 괜찮은 전략일 것 같습니다.
https://datascience.stackexchange.com/questions/84336/why-is-it-okay-to-set-the-bias-vector-up-with-zeros-and-not-the-weight-matrices
Pytorch에서는 가중치 초기화가 어떤식으로 세팅되어 있을까요?
Linear Layer 에서의 예시
def __init__(self, in_features: int, out_features: int, bias: bool = True,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
if bias:
self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self) -> None:
# Setting a=sqrt(5) in kaiming_uniform is the same as initializing with
# uniform(-1/sqrt(in_features), 1/sqrt(in_features)). For details, see
# https://github.com/pytorch/pytorch/issues/57109
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
init.uniform_(self.bias, -bound, bound)https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/linear.py
Conv Layer 에서의 예시
https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/conv.py#L40
He Uniform 이 아니라 Xavier Uniform 이 사용하고 싶다면?
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_uniform_(m.weight)
torch.nn.init.zeros_(m.bias)
model.apply(weights_init)
참고 )
https://deepestdocs.readthedocs.io/en/latest/002_deep_learning_part_1/0025/
https://discuss.pytorch.org/t/how-are-layer-weights-and-biases-initialized-by-default/13073/34
수식 위주의 설명 & 구현 실습 )
https://www.youtube.com/watch?v=Z3fRsrhfSmo
https://www.youtube.com/watch?v=miKqL893ZjU
https://www.youtube.com/watch?v=Dkar0jrqz-U&list=PLgaemU2xZlThNt7H4QlyLcWJDN7NeVBA3&index=2
'DL > Basic' 카테고리의 다른 글
| Cross Entropy 맛보기 (0) | 2024.05.09 |
|---|---|
| Optimizer (1) | 2024.05.08 |
| 1 x 1 Conv (1) | 2023.12.06 |
| Plateau Problem (0) | 2023.05.25 |
| What is Deeplearning? (1) | 2023.05.14 |
가중치 초기값을 0으로 해버리면 안되나요?
가중치 초기화를 0으로 해버리면, 위 식에서와 같이 결국 x 앞단의 모든 값들에 대해 기울기가 0으로 전파되면서 학습이 일어나지 않게 된다.
가중치 초기값을 상수값으로 해버리면 안되나요?
모든 노드에 Feature가 대칭적으로, 똑같은 값이 전파되면서 학습이 제대로 이루어지지 않는다.
따라서 난수로 가중치를 초기화함으로써 대칭을 파괴해야한다.
Redundancy로 보는 해석도 있어서 첨한다.
가중치 상수 값이라는것은, 같은 선형 지역을 탐색하겠다는 것이므로,
당연히 탐색이 제대로 이루어지지 않을 것이다.
그럼 Random Initialization 했을 때 문제점은 없을까요?
가중치가 매우 낮은 값으로 초기화 될 경우, 기울기 소실 문제가 발생할 수 있고,
가중치가 매우 높은 값으로 초기화 될 경우, 기울기 폭발 문제가 발생할 수 있는 문제가 있습니다.
따라서 네트워크에 맞는 적절한 가중치 초기화 기법을 사용하여 학습이 원활하게 진행될 수 있도록 하여야 합니다.
Xavier Glorot Initialization 에 대해 설명해주세요.
- Xavier Normal Initialization
- Xavier Uniform Initialization
Sigmoid, Tanh 계열의 활성화 함수에서 각 레이어에서 나오는 출력 값의 분산이 너무 커지면, 포화 영역으로 값이 밀려나게 되면서 기울기 소실 현상이 발생할 수 있습니다.
(값이 양 끝단으로 밀려나게 되면, 기울기가 점근선에 가까워지게 됩니다.)
Xavier Initialization은 레이어로 전달되는 정보의 분산이 일정하도록 Weight를 초기화하여 이를 극복할 수 있습니다.
Kaiming He initialization 에 대해 설명해주세요.
- He Normal Initiaization
- He Uniform Initialization
Relu 활성화 함수가 대중적으로 사용되게 되면서, Relu 함수에 맞는 초기화 방법도 나오게 됐는데, 그게 바로 He Initialization 입니다.
활성화 함수 Relu를 사용할 때, Xavier 초기화를 사용하게 되면, 음수 구간에서 노드가 꺼지기 때문에 데이터의 분산이 점점 작아지게 됩니다.
He 초기화에서는 이에 대해 가중치 분산 값을 키워, 레이어로 전달되는 정보의 분산이 일정할 수 있도록 하였습니다.
Bias는 어떻게 초기화하나요?
Bias는 일반적으로 0으로 초기화한다고 합니다.
아래 글에 Bias를 왜 0으로 초기화해도 되는지에 대한 답안이 나와있는데요,
"가중치 난수 초기화로 선형 독립성이 어느정도 보장된다면 Bias는 0으로 해도 전혀 문제 없다." 정도로 저는 해석하였습니다. 만약 그렇다면 모델이 Zero 부터 학습할 수 있도록 하는 것도 괜찮은 전략일 것 같습니다.
https://datascience.stackexchange.com/questions/84336/why-is-it-okay-to-set-the-bias-vector-up-with-zeros-and-not-the-weight-matrices
Pytorch에서는 가중치 초기화가 어떤식으로 세팅되어 있을까요?
Linear Layer 에서의 예시
def __init__(self, in_features: int, out_features: int, bias: bool = True,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super().__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))
if bias:
self.bias = Parameter(torch.empty(out_features, **factory_kwargs))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self) -> None:
# Setting a=sqrt(5) in kaiming_uniform is the same as initializing with
# uniform(-1/sqrt(in_features), 1/sqrt(in_features)). For details, see
# https://github.com/pytorch/pytorch/issues/57109
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
init.uniform_(self.bias, -bound, bound)https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/linear.py
Conv Layer 에서의 예시
https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/conv.py#L40
He Uniform 이 아니라 Xavier Uniform 이 사용하고 싶다면?
def weights_init(m):
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_uniform_(m.weight)
torch.nn.init.zeros_(m.bias)
model.apply(weights_init)
참고 )
https://deepestdocs.readthedocs.io/en/latest/002_deep_learning_part_1/0025/
https://discuss.pytorch.org/t/how-are-layer-weights-and-biases-initialized-by-default/13073/34
수식 위주의 설명 & 구현 실습 )
https://www.youtube.com/watch?v=Z3fRsrhfSmo
https://www.youtube.com/watch?v=miKqL893ZjU
https://www.youtube.com/watch?v=Dkar0jrqz-U&list=PLgaemU2xZlThNt7H4QlyLcWJDN7NeVBA3&index=2
'DL > Basic' 카테고리의 다른 글
| Cross Entropy 맛보기 (0) | 2024.05.09 |
|---|---|
| Optimizer (1) | 2024.05.08 |
| 1 x 1 Conv (1) | 2023.12.06 |
| Plateau Problem (0) | 2023.05.25 |
| What is Deeplearning? (1) | 2023.05.14 |