
정리하게 된 계기
from sklearn.cluster import KMeans
# r,g,b 단위로 한줄로 reshape
X = image.reshape(-1,3)
# 비슷한 색상(군집) 8개로 모음
kmeans = KMeans(n_clusters=8,random_state=13).fit(X)
# 센터값만 저장
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
# 센터 값을 이미지로 바꿔서 봄
segmented_img = segmented_img.reshape(image.shape)
답변
스터디 팀원 분께서 관련한 링크를 찾아 보내주셨다.
링크 : https://bytemeta.vip/repo/ageron/handson-ml2/issues/489
[QUESTION] Chap 9 - cluster for image segmentation - bytemeta
[QUESTION] Chap 9 - cluster for image segmentation
bytemeta.vip
numpy advanced indexing 이라고 쳐보면 예제가 다양하게 나오는데 그 가운데 있는 것 같았다.
나는 검색해도 나오지가 않아서 그냥 위 링크의 답변 보고 혼자 실습해 보는것으로 해서 이해하고 끝냈다.
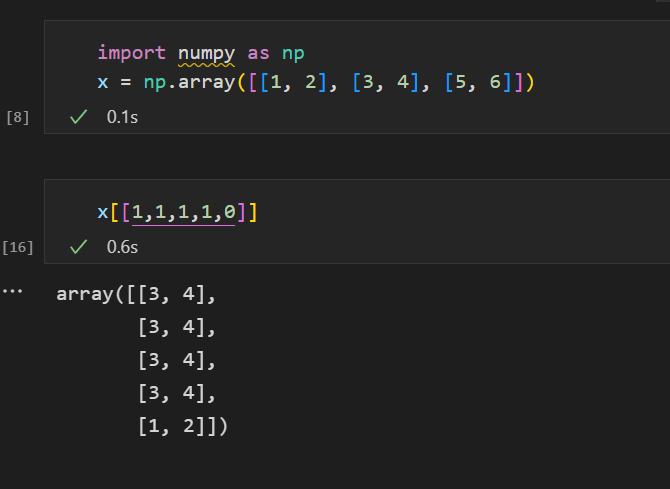
다음과 같이 2D array 안에 1D array를 조회하면,
1D array 안의 값이 마치 2D array 의 인덱스에 해당하는 것처럼 해서 참조하게 된다.
결국 스터디 팀원분의 말씀을 빌리면,
위의 처음의 질문에 대한 답은. 결국 각 라벨이 해당 군집의 중심점을 참조해서 라벨 마다 군집 중심점 좌표를 갖게 되는 것이다.
이미지 분석할 때, cluster로 몇개의 색상을 뽑아가지고 표현할 때 자주 쓰이는 방식인 것 같았다.
'EDA' 카테고리의 다른 글
| [2018 Data Science Bowl] Teaching notebook for total imaging newbies Kor 캐글 필사 (2) | 2022.09.20 |
|---|---|
| [Pandas] dictionery를 사용한 맞춤 정렬 (0) | 2022.09.11 |
| [SNS] Seaborn 의 factorplot을 이용해보자. (0) | 2022.07.19 |
| [SNS] seaborn을 가지고 만드는 막대차트 (0) | 2022.07.19 |
| [Pandas] groupby, crosstab 사용하기 (0) | 2022.07.19 |