

Output Configuration
Output Length
- Higher Cost, Slower Response Time을 고려하여 적절히 제한
Sampling Controls
- Temperature (T)
- Next Token Prediction에 대해, 마치 Softmax Func을 생각하면 됨.
- 0에 가까울수록, 분포가 뾰족해짐 (= Greedy Decoding, 정해진 답변, 결정론적)
- 1에 가까울수록, 분포가 느슨해짐 (= 불확실성 강화, 창의적인 답변, 무작위)
- Top-K
- 다음으로 올 Token에 대해, Top K 개의 토큰들 만큼을 후보로 가져오겠다.
- K = 1 (= Greedy Decoding, Next Token에 대한 후보가 1개)
- Top-P
- 토큰 누적 확률 샘플링, 토큰들을 학률이 높은 것부터 누적하여, 누적 확률의 임계값이 p에 도달할 때 까지 후보로 남김
- P = 0 (= Greedy Decoding, 하나의 토큰만을 가져옴)
- P = 1 (= All Tokens in the LLM's Vocab)
Sampling Controls 간 상관관계
더보기
If T = 0, (학률에 대한 타협 없이 하나의 토큰만 보겠다.)
K와 P는 아무런 효과가 없다.
If K = 1, (하나의 토큰만 후보로 두겠다.)
T와 P는 아무런 효과가 없다.
If P = 0, (하나의 토큰만 쓰겠다.)
T와 K는 아무런 효과가 없다.
General Setting 가이드
더보기
- Prompt를 이해하고 적당한 답변을 해내는 정도
- T = 0.2, P = 0.95, K = 30
- 창의적인 답변을 원할 경우
- T = 0.9, P = 0.99, K = 40
- 보다 관련성 있는 답변을 원할 경우
- T = 0.1, P = 0.9, K = 40
- 하나의 반복적인 단일 답변을 원할 경우
- T = 0
( 주의! ) "Repetition Loop bug"
더보기
Temperature Setting이 너무 높거나, Top-P가 너무 낮으면, 같은 단어가 반복해서 나오는 Repettion Loop Bug를 유발할 수 있습니다.
Prompt Techniques
General Prompting / Zero Shot

One-Shot & Few Shot
- Example 넣는 방식
- 출력 구조, 패턴 학습
- Few Shot의 경우 3 ~ 5개의 예시가 권장되며, 다양하고, 품질 높고, 관련성 있는 예시와, 견고성 향상을 위한 엣지 케이스를 포함하는 것이 좋다.


System, Contextual and role prompting
- System Prompting
- 모델의 Fundamental Capabilities and Overarhing Purpose
- Task 지시문, Schema 정의 등등
- ‘You should be respectful in your answer.’ 과 같은 강조, 경고 등의 문구 등
- Contextual Prompting
- 모델이 참고해야할 배경 지식
- Role Prompting
- Model이 어떤 역할을 수행해야 하는지
- tone, style, focused expertise 등에 대한 청사진
- 추천 키워드: Confrontational, Descriptive, Direct, Formal, Humorous, Influential, Informal, Inspirational, Persuasive
- 예시 )
- " I want you to act as a travel guide. I will write to you about
my location and you will suggest 3 places to visit near me in
a humorous style. "
- " I want you to act as a travel guide. I will write to you about
Advanced Techniques
Step-back Prompting
- 특정 질문에 답하기 전에, 추상적이거나 일반적인 질문을 먼저 생각하게 하여 배경 지식과 추론 과정을 활성화 하여, 이를 바탕으로 답하는 방식.
- Final Prompt를 LLM의 매개변수를 보다 잘 활용하는 방향으로 튜닝하는 방식.
- 일반적인 원칙에 초점을 맞추도록 유도함으로써, LLM 응답의 편향을 완화할 수 있습니다.
- Step-back 하지 않았을 때.
- Final Prompt: " 비디오 게임에 대한 스토리 라인을 써줘 "

- Step-back 했을 때.
- Step-back Prompt: "현존하는 유명한 FPS 게임 중 인기가 있는 5가지 이유들 답변해줘."
- Final Prompt: [Context] + 이 중 하나를 선택하여, 게임에 알맞는 스토리 라인을 써줘


Chain of Thought (CoT)
- 복잡한 문제 해결을 위해 중간 추론 단계 생성하도록 유도
- 해석 가능성, LLM 차이에 덜 의존한 기법
- 수학 문제의 경우, Large Volumes of Text를 학습하는 방식과는 다른 Approach가 요구되는 과제이기 때문에 단순한 문제임에도 불구하고, CoT 적용이 더 효과적일 수 있습니다.
- '말로 설명하며 풀 수 있는 (talking through)' 문제에 적합하며, Temperature 0 이 권장됩니다. (Greedy Decoding)
- Zero Shot 했을 때.
- "Let's think step by step."
- 다소 복잡함. ( = 3 * 3 + (20 - 3) )
- 내 나이 3살 때, 파트너 나이 계산
- 지금의 나와 3살 때의 나, 나이 차이 계산
- 내 나이 3살 때의 파트너 나이에 앞서 계산한 차이 더함

- Few Shot 했을 때.
- 내가 생각하는 계산 방식을 말로 풀어서 설명
- 단순해짐 ( = 20 + ( 9 - 3 ) )
- 내 나이 3살일 때, 파트너 나이 계산.
- 내 나이와 파트너 나이 차이 계산.
- 현재 내 나이로 파트너 나이 계산.

Self-Consistency
- CoT는 Greedy Decoding Strategy 으로, LLM의 잠재력을 충분히 뽑아내지 못하는것 같음.
- Sampling 과 Majority Voting을 결합한 전략
- 높은 Temperature 사용으로, 다양한 추론 경로 뽑아내고, 그 중 가장 일관성 있는 경로 채택
- Self-Consistency는 추론 경로를 단위로 A pseudo-probability likelihood of an answer being correct 를 내는 셈.
- 예시
더보기
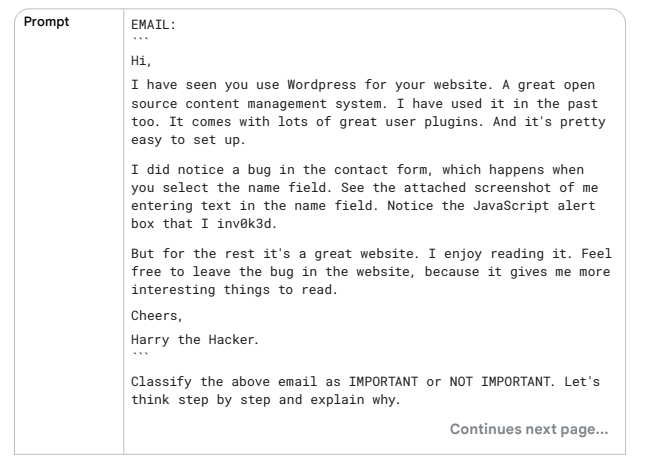

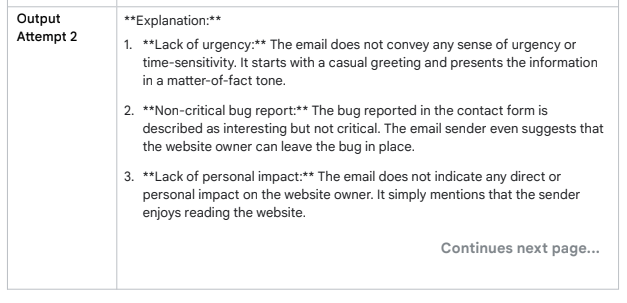


두 표를 받은 "IMPORTANT" 채택.
Tree of Thoughts (ToT)
- CoT에 대한 일반화된 방식. Not Single Linear CoT.
- Explore Multiple Different Reasoning Paths Simultaneously
- Output을 마치 토큰 처럼 선택해나감.
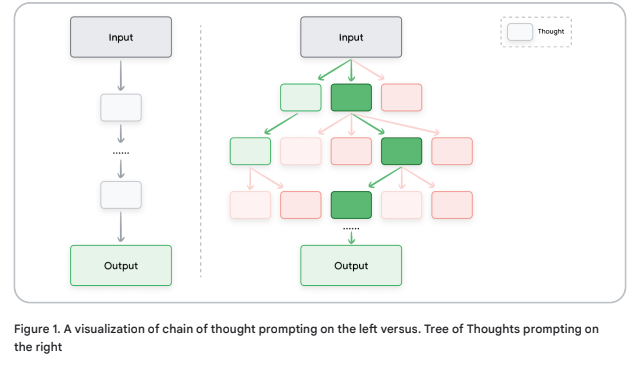
- Method
더보기
- Thought Decomposition
- 단계를 나누는 방식 결정 (단위 결정)
- Thought Generator
- 단계를 생성하는 방식 결정 (i.i.d sample prompt V.s. sequential propose prompt)
- State Evaluator
- 각 State가 Branch를 확장해도 되는지 여부 평가 (Judging by LLM V.s. Voting)
- Search Algorithm
- 단계를 확장해나가는 방식 결정 (BFS v.s. DFS w/ backtracking)
ReAct (reason & act)
- Agent
- 대화의 기록 관리가 중요


Automatic Prompt Engineering (APE)
- LLM을 사용하여 자동으로 프롬프트를 생성하고, BLEU, ROUGE 와 같은 지표로 평가하여 최적의 프롬프트를 찾아내는 방법
- 고객이 밴드 상품 티셔츠를 구매할 때, 주문을 표현할 수 있는 다양한 방법을 챗봇으로 학습하고 싶을 경우
- 프롬프트 후보를 뽑고, 이를 평가하여 사용

Tips for Prompt Engineering
1. 예시 작성 (Shot 활용)
- 표본을 대표할 수 있도록, 다양하게, Edge Case도 넣고.
2. 간결하고 명확한 설계
- Using Verbs that describe the action.

3. 구체적인 출력 형태 정의
- 원하는 결과물의 형식, 톤, 구조 등

4. Use Instructions over Constraints
- Constraints(제약)보다 Instruction(해야하는 것)에 대해 더 많이 넣어야 좋은 답변을 더 많이 내놓는다.

5. Prompt를 통해 Token Limit을 작성할 수 있다.
- "Explain quantum physics in a tweet length message."
6. 변수를 작성할 수 있다.
- 어플리케이션 연동시 유용하다.
- 재사용성

7. 질문, 문장, 지시 사항 등 여러 형태로 실험해보며 최적화할 수 있다.

8. Few Shot 분류 시 클래스 혼합
- 클래스의 순서에 과적합되지 않도록, 섞어주는 것이 좋다.
9. 모델 업데이트에 따른 조정
- 모델이 업데이트 되면 프롬프트의 성능이 달라질 수 있다.
10. Output 형식도 다양하게 조정해볼 수 있다.
- XML, JSON 등
- json-repair 라는 유용한 파이썬 라이브러리도 있다.
- time field도 양식에 포함하면, LLM이 시간 인식도 할 수 있다.


11. 여럿이서 실험하면 좋다.
- 다양한 버전 간의 Performance 비교해볼 수 있겠다.
12. CoT's 팁
- Temperature 0, Single correct answer
- Reasoning 순서 중요하다.
- Final Answer을 낼 때의 토큰 후보군에 영향 미치기에
13. 사용했던 프롬프트 다 기록해놓으세요.
- 모델, 샘플링 설정, 동일한 모델의 다른 버전에 따라 프롬프트 출력은 다 다를 수 있습니다.
- 두 토큰이 동일한 예측 확률을 가질 경우, 같은 조건임에도 출력이 또한 달라질 수 있습니다. ( 이는 예측된 토큰에 영향을 끼칩니다. )
- Result는 OK / Not OK / Sometimes OK 등으로 구분할 수 있겠습니다.
- RAG를 작업할 때는, 쿼리, 청크 설정, 청크 출력, 등 기타 정보를 포함하여, 프롬프트에 삽입된 콘텐츠 생성에 영향을 미치는 RAG 시스템 측면에서도 기록되어야 합니다.
- 잘 동작하는 프롬프트는 코드베이스에서 다른 프롬프트와 별도로 관리하면 유지 관리가 더 쉬워질 수 있습니다.
- 프롬프트 엔지니어링은 반복적인 프로세스 입니다. 다양한 프롬프트를 제작하고 테스트하여 결과를 분석하고 문서화합니다.
- 모델 또는 모델 구성이 바뀌면, 돌아가서 이전에 사용했던 프롬프트를 실험하는게 좋습니다.

참고로 이 백서는 Vertex AI와 Gemini 모델 환경을 기반으로 합니다.
작성하며 참고한 자료.
1) 구글 백서 https://drive.google.com/file/d/1AbaBYbEa_EbPelsT40-vj64L-2IwUJHy/view
2) 용혜림님 유투브 https://www.youtube.com/watch?v=EZqY_mnHfTI&t=963s
3)문주님 블로그 https://mz-moonzoo.tistory.com/88
'근황 토크 및 자유게시판' 카테고리의 다른 글
| [파이썬 의존성 관리] UV 설치 및 사용 (0) | 2025.04.28 |
|---|---|
| 내일, 네이버 1차 기술 면접을 봅니다. (2) | 2025.04.15 |
| [서평] 데이터 과학을 위한 소프트웨어 엔지니어링, 제이펍 출판사 (4) | 2025.03.11 |
| [Cuda 11.8] unsupported Microsoft Visual Studio version! (0) | 2025.01.27 |
| [Win10, Win11] AMD 드라이버 충돌 문제 (4) | 2025.01.24 |