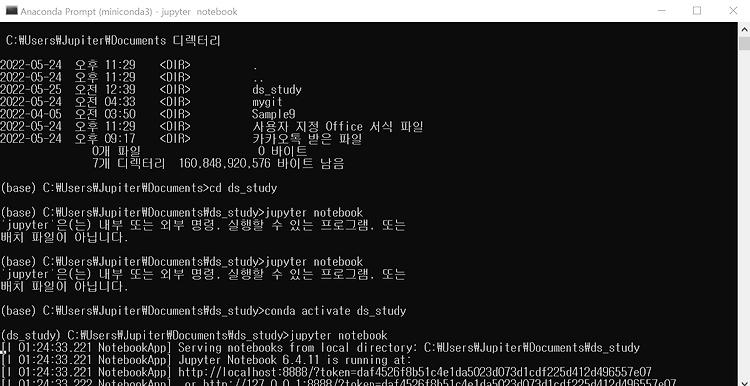
사전에 서울시 CCTV 현황 csv 파일과 구별 인구통계 엑셀 파일을 폴더에 저장해두었습니다.
1. 파일이 있는 곳에서 쥬피터 노트북을 열어줍니다.
jupyter notebook
콘다 환경을 활성화 안해줘서 오류가 났었네요. 잊지말고 쥬피터를 깔아둔 콘다 환경을 항상 먼저 activate 하도록 합시다.
2. 파일을 하나 만들어 CCTV 통계 CSV 파일을 불러와 봅시다.
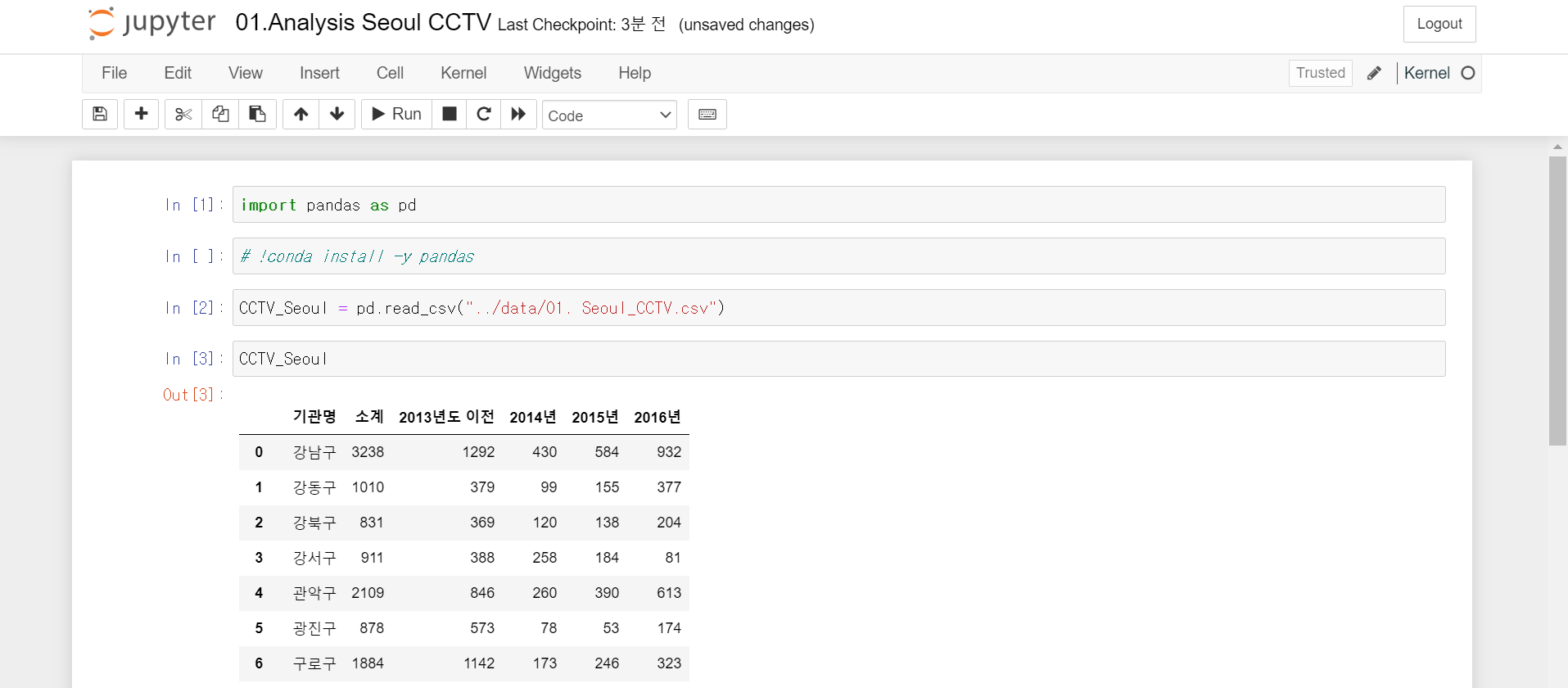
import pandas as pd
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv")read_csv() 로 csv 파일을 읽어옵니다.
경로에서 ../ 는 현재 파일 위치의 상위 폴더를 의미합니다.
현재 파일은 utf-8로 인코딩된 파일이라 깨짐 현상이 발생하지 않는데, 만약 깨진다면
df = pd.read_csv('파일경로', encoding='utf-8')다음처럼 utf-8로 인코딩해 읽어온다면, 깨짐 문제를 해결할 수 있습니다.
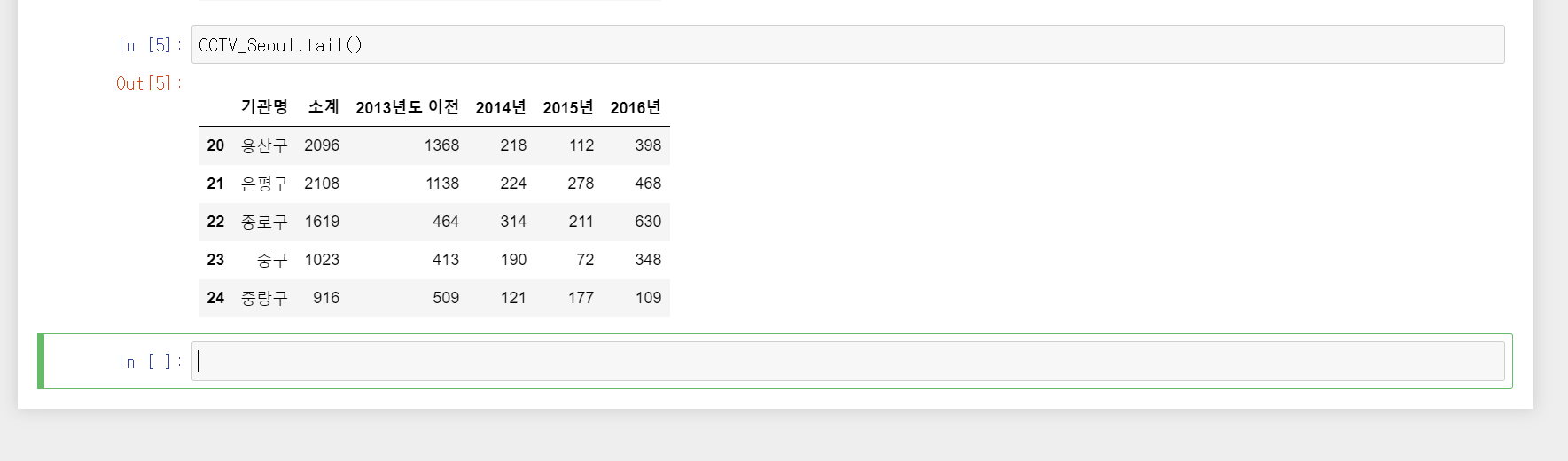
3. 파일의 꼬리부분을 봐봅시다.
CCTV_Seoul.head()
CCTV_Seoul.tail()head()는 앞에서 5줄, tail은 끝에서 5줄을 불러오는 함수 입니다.
안에 숫자 n을 넣어준다면, n줄 만큼을 읽어오게 됩니다.
tail을 쓰면 데이터가 몇줄인지 파악이 되기 때문에 유용하다고 합니다.
4. 칼럼 명을 바꿔 줍시다.
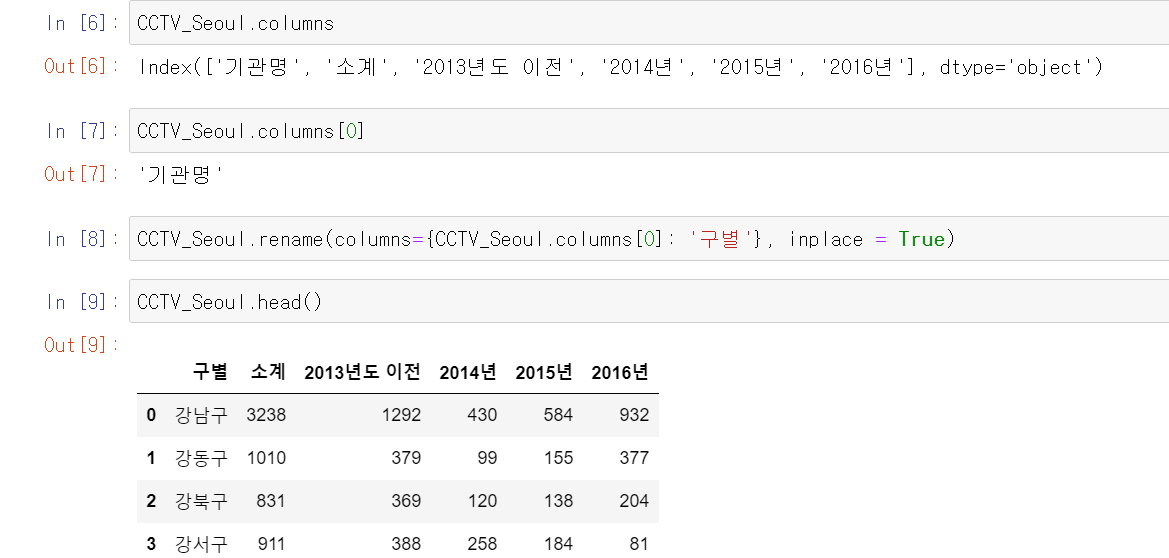
CCTV_Seoul.columns # 칼럼 명을 보여줍니다.
CCTV_Seoul.columns[0] # 리스트에서와 마찬가지로 요소를 조회할 수 있습니다.
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: '구별'}, inplace = 'True')inplace 는 원본 데이터를 바꿀지에 대한 인수를 넣는 것 입니다.
5. 이번에는 서울 인구수 통계 엑셀 파일을 불러오겠습니다.

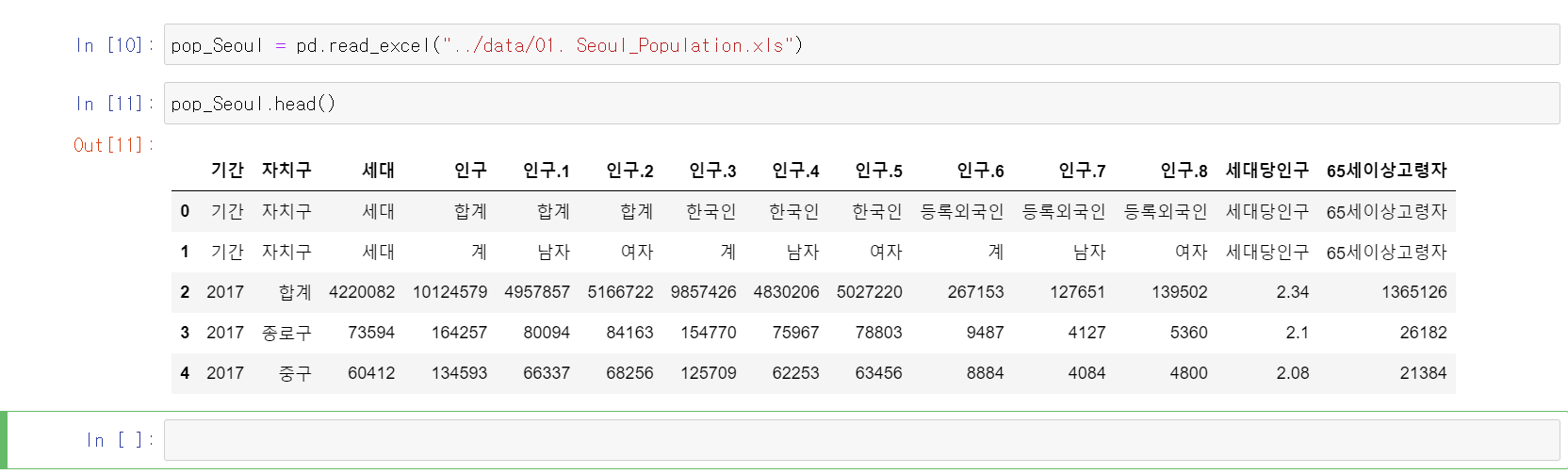
pop_Seoul = pd.read_excel("파일 경로")불러오긴 했지만, 불필요한 칼럼 네임과 칼럼 까지 불러와졌습니다.
참고로 CSV 파일의 경우에는 자동 셀 병합 기능을 지원 하지만 엑셀 같은경우에는 그렇지 못하다고 하네요.
6. 불필요한 column 들을 좀 정리해주겠습니다.
필요한 열은 , B, D, G, J, N 입니다.
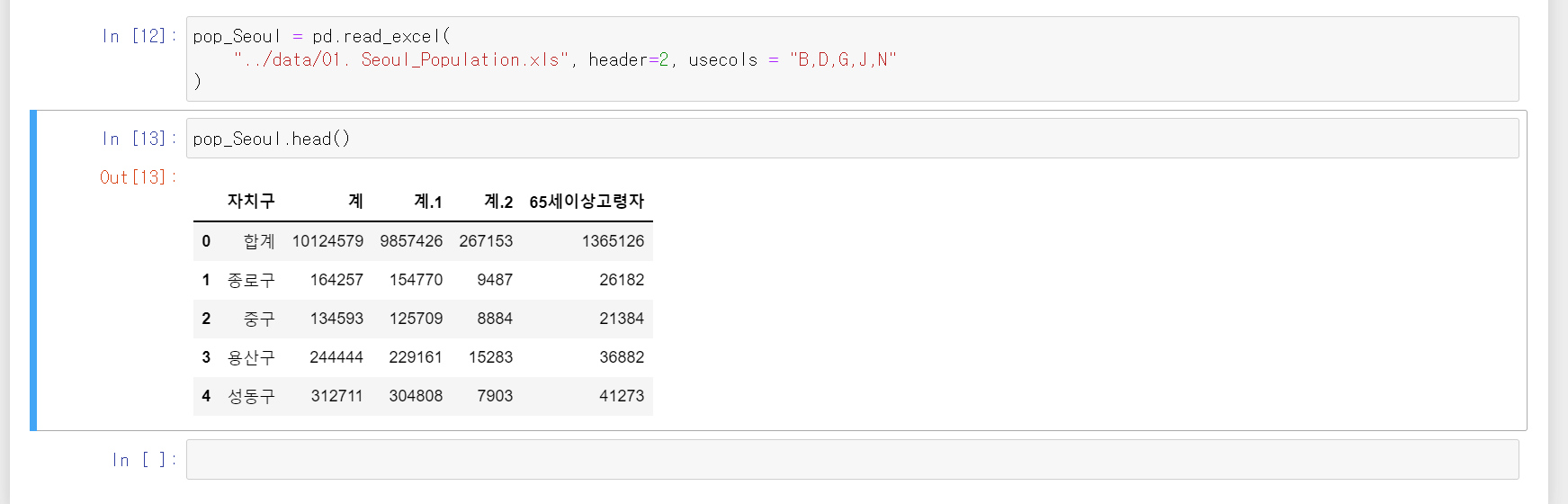
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols = "B,D,G,J,N"
)header에는 column name을 몇 줄 날릴지를 적습니다.
usecols 에는 가져올 열을 선택합니다. ( 가져올 열은 원본 데이터를 보고 결정합니다. )
7. rename 함수를 통해 칼럼명을 바꿔주겠습니다.
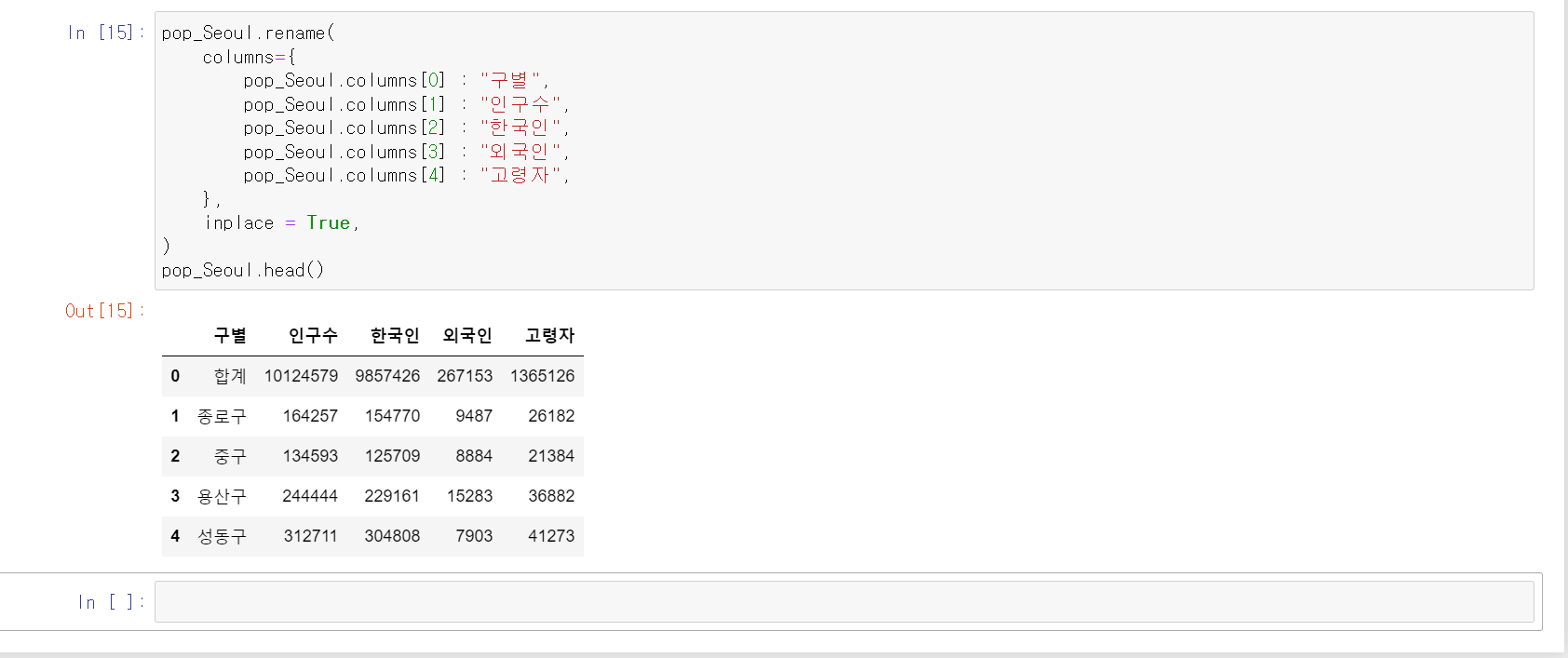
pop_Seoul.rename(
columns = {
pop_Seoul.columns[0] : "구별",
pop_Seoul.columns[1] : "인구수",
pop_Seoul.columns[2] : "한국인",
pop_Seoul.columns[3] : "외국인",
pop_Seoul.columns[4] : "고령자",
},
inplace = True,
)
pop_Seoul.head()
🌮 배운 코드 정리
import pandas as pd # 판다스를 pd라는 이름으로 불러오겠습니다.
!conda install -y pandas # 판다스가 설치가 안되어있다면 설치를 해 줍시다.
CCTV_Seoul = pd.read_csv("파일 경로") # csv 파일을 읽어옵니다.
df = pd.read_csv('파일 경로', encoding='utf-8') # 한글이 깨진다면 encoding을 utf-8로 불러옵니다.
CCTV_Seoul.head() # 칼럼명 제외한 5줄만 볼 수 있습니다.
CCTV_Seoul.head(3) # 이러면 3줄만 불러오게 됩니다.
CCTV_Seoul.tail() # 이러면 끝에서 5줄을 불러옵니다.
CCTV_Seoul.columns # 칼럼 명을 보여줍니다.
CCTV_Seoul.columns[0] # 리스트에서와 마찬가지로 요소를 조회할 수 있습니다.
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: '구별'}, inplace = 'True')pop_Seoul = pd.read_excel("파일 경로")
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols = "B,D,G,J,N"
)
pop_Seoul.rename(
columns = {
pop_Seoul.columns[0] : "구별",
pop_Seoul.columns[1] : "인구수",
pop_Seoul.columns[2] : "한국인",
pop_Seoul.columns[3] : "외국인",
pop_Seoul.columns[4] : "고령자",
},
inplace = True,
)
pop_Seoul.head()
구글에 pandas read_excel documentation 와 같이 검색하면, 판다스 read_excel 함수에 대한 자세한 설명이 나와있다고 합니다.
진짜 정말정말 꿀팁이에요.
'DS_Study > 서울시 CCTV 현황' 카테고리의 다른 글
| [DS_study] pandas dataframe 정렬, 선택, 조회 (0) | 2022.05.25 |
|---|---|
| [DS_study] pandas 기초, DataFrame 선언 및 정보 탐색 (0) | 2022.05.25 |
| [DS_study] pandas 기초, pd.Series(), pd.date_range() (0) | 2022.05.25 |
| [DS_study] 쥬피터로 필기를 해봅시다. (0) | 2022.05.25 |
| [DS_study] 쥬피터에서 한 작업 VS code에서 다시 해보기 (0) | 2022.05.25 |
사전에 서울시 CCTV 현황 csv 파일과 구별 인구통계 엑셀 파일을 폴더에 저장해두었습니다.
1. 파일이 있는 곳에서 쥬피터 노트북을 열어줍니다.
jupyter notebook콘다 환경을 활성화 안해줘서 오류가 났었네요. 잊지말고 쥬피터를 깔아둔 콘다 환경을 항상 먼저 activate 하도록 합시다.
2. 파일을 하나 만들어 CCTV 통계 CSV 파일을 불러와 봅시다.
import pandas as pd
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv")read_csv() 로 csv 파일을 읽어옵니다.
경로에서 ../ 는 현재 파일 위치의 상위 폴더를 의미합니다.
현재 파일은 utf-8로 인코딩된 파일이라 깨짐 현상이 발생하지 않는데, 만약 깨진다면
df = pd.read_csv('파일경로', encoding='utf-8')다음처럼 utf-8로 인코딩해 읽어온다면, 깨짐 문제를 해결할 수 있습니다.
3. 파일의 꼬리부분을 봐봅시다.
CCTV_Seoul.head()
CCTV_Seoul.tail()head()는 앞에서 5줄, tail은 끝에서 5줄을 불러오는 함수 입니다.
안에 숫자 n을 넣어준다면, n줄 만큼을 읽어오게 됩니다.
tail을 쓰면 데이터가 몇줄인지 파악이 되기 때문에 유용하다고 합니다.
4. 칼럼 명을 바꿔 줍시다.
CCTV_Seoul.columns # 칼럼 명을 보여줍니다.
CCTV_Seoul.columns[0] # 리스트에서와 마찬가지로 요소를 조회할 수 있습니다.
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: '구별'}, inplace = 'True')inplace 는 원본 데이터를 바꿀지에 대한 인수를 넣는 것 입니다.
5. 이번에는 서울 인구수 통계 엑셀 파일을 불러오겠습니다.
pop_Seoul = pd.read_excel("파일 경로")불러오긴 했지만, 불필요한 칼럼 네임과 칼럼 까지 불러와졌습니다.
참고로 CSV 파일의 경우에는 자동 셀 병합 기능을 지원 하지만 엑셀 같은경우에는 그렇지 못하다고 하네요.
6. 불필요한 column 들을 좀 정리해주겠습니다.
필요한 열은 , B, D, G, J, N 입니다.
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols = "B,D,G,J,N"
)header에는 column name을 몇 줄 날릴지를 적습니다.
usecols 에는 가져올 열을 선택합니다. ( 가져올 열은 원본 데이터를 보고 결정합니다. )
7. rename 함수를 통해 칼럼명을 바꿔주겠습니다.
pop_Seoul.rename(
columns = {
pop_Seoul.columns[0] : "구별",
pop_Seoul.columns[1] : "인구수",
pop_Seoul.columns[2] : "한국인",
pop_Seoul.columns[3] : "외국인",
pop_Seoul.columns[4] : "고령자",
},
inplace = True,
)
pop_Seoul.head()
🌮 배운 코드 정리
import pandas as pd # 판다스를 pd라는 이름으로 불러오겠습니다.
!conda install -y pandas # 판다스가 설치가 안되어있다면 설치를 해 줍시다.
CCTV_Seoul = pd.read_csv("파일 경로") # csv 파일을 읽어옵니다.
df = pd.read_csv('파일 경로', encoding='utf-8') # 한글이 깨진다면 encoding을 utf-8로 불러옵니다.
CCTV_Seoul.head() # 칼럼명 제외한 5줄만 볼 수 있습니다.
CCTV_Seoul.head(3) # 이러면 3줄만 불러오게 됩니다.
CCTV_Seoul.tail() # 이러면 끝에서 5줄을 불러옵니다.
CCTV_Seoul.columns # 칼럼 명을 보여줍니다.
CCTV_Seoul.columns[0] # 리스트에서와 마찬가지로 요소를 조회할 수 있습니다.
CCTV_Seoul.rename(columns={CCTV_Seoul.columns[0]: '구별'}, inplace = 'True')pop_Seoul = pd.read_excel("파일 경로")
pop_Seoul = pd.read_excel(
"../data/01. Seoul_Population.xls", header=2, usecols = "B,D,G,J,N"
)
pop_Seoul.rename(
columns = {
pop_Seoul.columns[0] : "구별",
pop_Seoul.columns[1] : "인구수",
pop_Seoul.columns[2] : "한국인",
pop_Seoul.columns[3] : "외국인",
pop_Seoul.columns[4] : "고령자",
},
inplace = True,
)
pop_Seoul.head()
구글에 pandas read_excel documentation 와 같이 검색하면, 판다스 read_excel 함수에 대한 자세한 설명이 나와있다고 합니다.
진짜 정말정말 꿀팁이에요.
'DS_Study > 서울시 CCTV 현황' 카테고리의 다른 글
| [DS_study] pandas dataframe 정렬, 선택, 조회 (0) | 2022.05.25 |
|---|---|
| [DS_study] pandas 기초, DataFrame 선언 및 정보 탐색 (0) | 2022.05.25 |
| [DS_study] pandas 기초, pd.Series(), pd.date_range() (0) | 2022.05.25 |
| [DS_study] 쥬피터로 필기를 해봅시다. (0) | 2022.05.25 |
| [DS_study] 쥬피터에서 한 작업 VS code에서 다시 해보기 (0) | 2022.05.25 |