DL/NLP
Transformer to T5 (두 줄 history, 2018 ~ 2019)
scone
2024. 7. 18. 20:34
출처 : DSBA 유투브, 이유경님 발표
Seq2Seq
- Neural Machine Translation
- Encoder - Decoder 구조의 모델 (RNN 기반의)
Attention + Seq2Seq
- Neural Machine Translation
- Decoder가 Source Sentence 의 중요한 정보에 집중하게 하자.
Transformer
- Neural Machine Translation
- Self Attention, Multi-Head Attention
GPT - 1
- Task Agnostic
- Transformer Decoder Block
- 언어 자체를 이해할 수 있는 좋은 Representation을 학습해보자!
- Pre training을 맞춘 뒤, Fine Tuning을 통해 Task를 다뤄보자 라고 제안.
BERT
- Task Agnostic; Pretraining + Finetuning
- Transformer Encoder Block
- 언어를 더 잘 이해하기 위해, Bidirectional 하게 맥락을 파악해보자!
- 당시 모든 NLP Task 에서 SOTA
GPT - 2
- Task Agnostic
- Zero shot task transfer
- 언어를 정확히 학습했다면, Finetuning 없이 Zeroshot 만으로 좋은 성능을 낼 수 있다~!
- 7가지 NLP Task 에서 SOTA (특히 Generation)
XLNet
- Task Agnostic
- BERT 이후 큰 성능향상을 보인 첫 모델
- BERT 와 GPT를 합친 모델 ( AE, AutoEncoder + AR, AutoRegressive )
- Factorization order를 고려하여 양방향 학습
- AR formula를 통해 BERT 한계 극복
RoBERTa
- Task Agnostic
- 가장 최적화된 BERT를 만들어보자!
- BERT를 Underfitting 되어있다고 가정 후, 학습 시간, Batch, Train DATA 증가
MASS
- Task Agnostic
- BERT와 GPT를 합친 모델 (AE + AR)
- Encoder와 Decoder에 상반된 Masking
- Decoder : Encoder에서 masking된 단어 예측
- Encoder : Masking되지 않은 단어 깊은 이해
- Encoder, Decoder의 joint training 장려
BART
- Task Agnostic
- BERT와 GPT를 합친 모델 (AE + AR)
- Encoder에 다양한 Noising을 추가한 Text Generation Task에서 SOTA 달성
MT-DNN
- Task Agnostic
- Based on BERT
- Multitask Learning 을 통해 Universal한 representation을 생성하는 모델
- Pretrain 단계에서 Multitask Learning 진행 -> 모든 NLP Task 에 Robust 한 모델 만들 수 있다.
T5
- Task Agnostic
- Encoder - Decoder Transformer ( AE + AR )
- 모든 NLP Task를 통합할 수 있도록, Text to text 프레임워크를 사용하자.
* AE? AR?
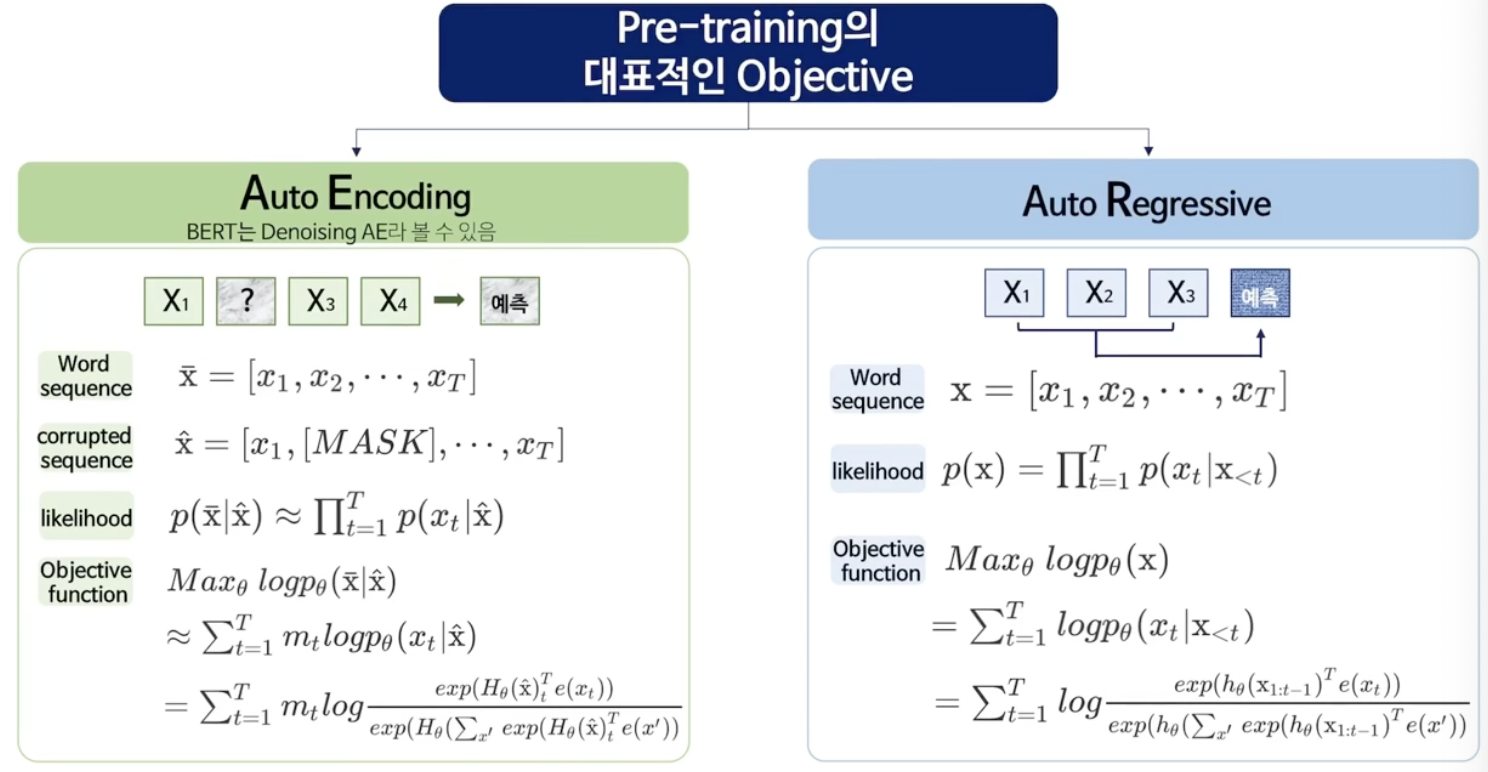
- AE의 단점
- [MASK] token 이 독립적으로 예측 됨.
- token 사이의 Dependency 학습할 수 없음.
- Finetuning 과정에서 [Mask] Token이 등장하기 않기 때문에, Pretraining과 Finetuning 사이에 discrepancy 발생함.
- AR의 단점
- 단일 방향 정보만 이용하여 학습 가능함.
모델들이 위 단점을 어떻게 해결하였고 어떻게 개선하였는지는 출처의 유투브에 소개되어 있다.