어떤 상황에서 Array나 Numpy를 쓰는 것이 적절할까?
본 글은 https://hyperconnect.github.io/2023/05/30/Python-Performance-Tips.html#2-built-in-list는-충분히-빠르지-않다-필요시-array나-numpy를-사용하자 의 내용을 공부하며 정리한 글 입니다.
어떤 상황에서 Array나 Numpy를 쓰는 것이 적절할까?
- 내부에 PyObject (객체)를 들고 있는 list
- PyObject **ob_item; 부분을 보면, 값을 조회하기 위해 참조를 두번 타고 들어가는 것으로 볼 수 있다.
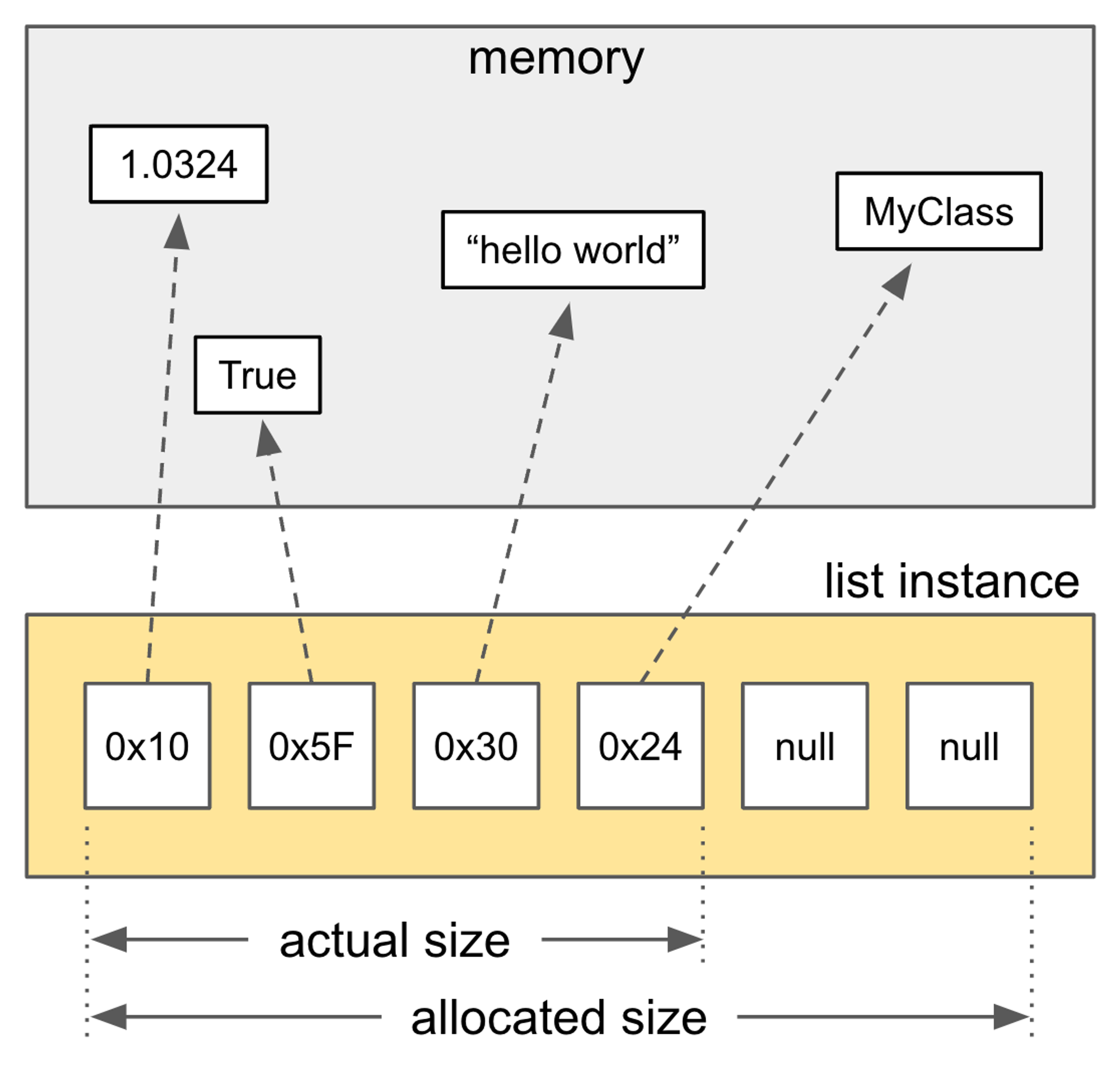
- 아래는 cpython에서 파이썬 list를 정의하는 부분이다.
- https://github.com/python/cpython/blob/main/Include/cpython/listobject.h
/* Python built-in list */
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
- Python built-in list 는 성능 하락을 야기할 수 있다 그 이유는?
- list는 포인터들의 배열, 즉 더블 포인터로 구성되어 있습니다. 이는 리스트 내에서는 인접한 요소들이더라도 실제 메모리 상에서는 요소들이 제각기 다른 주소에 흩어져 있을 수 있다는 뜻입니다.
- 따라서 cache locality가 떨어지고 cache miss가 더 자주 발생해 성능이 하락할 수 있습니다.CPython 에서의 list 구현
- 내부에 값을 들고 있는 Array
- char *obitem을 통해 시작점을 지정하고, Py_ssize_t를 통해 type에 따른 사이즈를 지정하는 것으로 볼 수 있다.
- https://github.com/python/cpython/blob/main/Modules/arraymodule.c#L43
/* Python built-in array */
typedef struct arrayobject {
PyObject_VAR_HEAD
char *ob_item;
Py_ssize_t allocated;
const struct arraydescr *ob_descr;
PyObject *weakreflist; /* List of weak references */
Py_ssize_t ob_exports; /* Number of exported buffers */
} arrayobject;
- Python built-in array는 list와 어떠한 점이 다른가?
- list와 달리 array는 C의 array 처럼 연속된 메모리 공간에 값을 할당합니다.
- built-in array는 어떤 객체에 대한 레퍼런스를 들고 있는 것이 아니라, 값 자체를 들고 있기 때문에 locality가 보장됩니다. 대신 int, byte, float 등 primitive한 값만 저장할 수 있다는 제약이 존재합니다.
- 참고로 Numpy ndarray는…
- ndarray 또한 built-in array와 비슷하게 연속된 메모리 공간에 값을 할당, 빠른 메모리 접근 가능
- 다만 ndarray에서 dtype=’O’로 설정하여 객체를 저장하게 된다면, 객체에 대한 reference를 저장하기 때문에 built-in list와 동일한 방식으로 작동합니다. ( 링크 )
- list, array, numpy ndarray의 접근 성능 비교
import timeit
import array
import numpy as np
# Parameters for testing
N = 10000 # number of rows and columns in the array
M = 1000 # number of iterations
# Initialize the arrays
my_list = [i for i in range(N)]
my_array = array.array('i', my_list)
my_ndarray = np.array(my_list)
def test_list_sum():
sum(my_list)
def test_array_sum():
sum(my_array)
def test_numpy_sum():
sum(my_ndarray)
def test_numpy_npsum():
np.sum(my_ndarray)
# Perform the benchmarks
list_time = timeit.timeit(test_list_sum, number=M)
array_time = timeit.timeit(test_array_sum, number=M)
ndarray_sum_time = timeit.timeit(test_numpy_sum, number=M)
ndarray_npsum_time = timeit.timeit(test_numpy_npsum, number=M)
# Output the results
print(f'list: {list_time * 1000:.1f} ms')
print(f'array: {array_time * 1000:.1f} ms')
print(f'ndarray (sum): {ndarray_sum_time * 1000:.1f} ms')
print(f'ndarray (np.sum): {ndarray_npsum_time * 1000:.1f} ms')
list: 72.0 ms
array: 126.4 ms
ndarray (sum): 373.0 ms
ndarray (np.sum): 2.5 ms
⇒ ndarray의 경우 np.sum()을 썼을 때는 압도적으로 빠른 성능을 보여주지만 그냥 sum을 했을 때는 list가 array나 ndarray보다 오히려 빠릅니다. 왜 그럴까요?
- Built in list의 경우
Built-in list의 경우 test_list_sum() 함수를 실행할 때 memory read → arithmetic operation (+) 이 순차적으로 일어납니다.
- 그런데 array나 ndarray는 다릅니다.따라서 test_array_sum() 이나 test_numpy_sum() 함수를 실행할 때는 다음과 같은 연산이 수행됩니다.
- memory read → conversion (int -> Python object) → arithmetic operation (+)
- 이 변환의 오버헤드로 인해 list보다 더 나쁜 성능을 보이는 것으로 보입니다.
- python 객체가 아닌 primitive 값을 저장하기 때문에, python 로직(i.e. sum 함수)에서 값에 접근하기 위해서는 먼저 primitive value를 python 객체로 변환해야 합니다.
- np.sum()은 왜 빠를까요?
- Python 객체로 변환할 필요 없이 primitive 값에 대해 그대로 연산을 수행합니다.
- 모든 값을 C 로직에서 더한 뒤, 최종 결과를 Python 객체로 한 번만 변환하면 되므로 conversion overhead가 거의 없습니다.
- 그리고 C의 for loop이 python의 for loop보다 훨씬 오버헤드가 적고, 일부 연산의 경우 OpenMP와 같은 병렬 처리 기술을 활용할 수도 있어 월등히 빠른 것입니다.
- numpy를 통해 성능 향상을 극대화하기 위해서는
- indexing을 통해 하나씩 접근하는 것이 아니라, numpy에서 제공하는 별도의 operator를 사용하는 것이 중요하다.
- 만약 numpy에서 제공하지 않는 자체 함수를 사용해야 하는 경우, apply_along_axis() 와 같은 함수를 사용하면 그냥 for loop을 돌리는 것보다는 우수한 성능을 보일 때도 있습니다.
- 하지만 이 또한 pure-python 레벨에서 로직을 수행하는 것이므로 성능 향상을 최대로 가져가려면 최대한 vectorize된 operator를 활용하는 것이 좋겠죠.
list, array, numpy ndarray의 직렬화 성능 비교
- 예를 들어 배열에 담긴 값을 DB에 저장하거나 페이로드에 담아 보낼때 binary 데이터로 변환이 필요할 수 있습니다.
- 이때 array나 ndarray의 경우 이미 연속적인 메모리 공간에 binary 형태로 값이 저장되어 있기 때문에 값을 단순히 읽거나 copy해주면 되지만, list의 경우 메모리 공간 곳곳에 흩어져있는 각각의 값을 읽은 다음 이를 binary로 변환까지 거쳐야 하기 때문에 훨씬 느립니다.
- Python에서 널리 사용되는 직렬화/역직렬화 패키지 중 하나인 marshal을 이용해 marshal(직렬화), unmarshal(역직렬화) 성능을 비교해보겠습니다.
import timeit
import array
import numpyas np
import pickle
import marshal
import random
N= 10000# number of elements in the array
M= 1000# number of iterations
# Initialize the arrays
my_list= [random.random()for _in range(N)]
my_list_enc= marshal.dumps(my_list)
my_array= array.array('f', my_list)
my_array_enc= marshal.dumps(my_array)
my_ndarray= np.array(my_list, dtype=np.float32)
my_ndarray_enc= marshal.dumps(my_ndarray)
deftest_list_marshal():
marshal.dumps(my_list)
deftest_list_unmarshal():
marshal.loads(my_list_enc)
deftest_array_marshal():
marshal.dumps(my_array)
deftest_array_unmarshal():
marshal.loads(my_array_enc)
deftest_ndarray_marshal():
marshal.dumps(my_ndarray)
deftest_ndarray_unmarshal():
marshal.loads(my_ndarray_enc)
# Perform the benchmarks
list_marshal_time= timeit.timeit(test_list_marshal, number=M)
array_marshal_time= timeit.timeit(test_array_marshal, number=M)
ndarray_marshal_time= timeit.timeit(test_ndarray_marshal, number=M)
list_unmarshal_time= timeit.timeit(test_list_unmarshal, number=M)
array_unmarshal_time= timeit.timeit(test_array_unmarshal, number=M)
ndarray_unmarshal_time= timeit.timeit(test_ndarray_unmarshal, number=M)
...
[marshal]
list: 131.2 ms
array: 0.8 ms
ndarray: 1.9 ms
[unmarshal]
list: 155.4 ms
array: 0.9 ms
ndarray: 0.9 ms
⇒ marshal과 unmarshal 결과를 보면 list와 array, ndarray 사이에 상당한 속도 차이가 있습니다. 특히 list의 경우 다른 두 방식과 직렬화/역직렬화 시간이 무려 80~160배나 차이가 납니다. (다른 직렬화 패키지인 pickle을 사용하더라도 비슷한 결과를 관찰할 수 있습니다)
⇒ 이는 list의 경우 메모리공간 여기 저기에 흩어져 있는 데이터들을 취합해야 할 뿐만 아니라, 각각의 요소에 대해 data type을 확인한 뒤에 바이너리로 변환해야 해서 추가적인 overhead가 발생하기 때문으로 보입니다.
- 참고로 직렬화란?
- 직렬화(serialization)란 데이터 구조나 오브젝트 상태를 다른 컴퓨터 환경에서 저장하거나 전송할 수 있는 포맷(보통 바이트 스트림)으로 변환하는 과정을 말합니다.
- 역직렬화(deserialization)는 직렬화의 반대 과정으로, 데이터의 바이트 스트림을 다시 원래의 데이터 구조나 오브젝트로 복구합니다.
- 파이썬의 marshal 모듈은 파이썬 객체를 바이트 스트림으로 직렬화하는 데 사용됩니다.
- .pyc 파일(파이썬이 컴파일한 바이트코드가 저장되는 파일)을 생성할 때 사용됩니다.
- 네이버 부스트캠프 6기 프로젝트 중 사례
Hand - Bone X-Ray 분할 대회 과정 중, Data Set에서 라벨이 적힌 CSV와 손가락 뼈 사진에 대해, 29 개 클래스의 마스킹 이미지로 변화하여 이를 라벨로 사용하여 처리하는데 그 과정이 너무나도 오래 걸려 학습에 병목이 걸렸던 일이 있었습니다.
이를 사전에 오프라인에서 미리 마스킹 라벨로 바꿔놓으면 어떨까 하였지만, 데이터 용량이 약 500기가가 되는 것으로 확인하였고, 따라서 제공 받은 서버에서 이를 처리할 수 없었습니다.
저희는 마스킹 이미지를 np.array를 통해 만들어두었고, 이를 다시 np.packbits를 통해 압축하여 저장해두었습니다.
결과적으로 1epoch당 학습시간을 50%로 감소시킬 수 있었고, 이는 np.array로 파일을 압축시켰고, np.array로 파일을 읽어옴으로써 그렇게 시간이 단축될 수 있었던 것이 아니었나 싶습니다.
정리
- 단순히 numpy나 array를 사용한다고 해서 항상 속도가 빨라지는 것은 아니다.
- numpy를 사용하여 성능 증가 효과를 보려면, numpy에서 제공하는 별도의 operator를 사용하는 것이 중요하다.
- 직렬화 오버헤드가 큰 상황이라면, array나 ndarray를 사용해서 실행 속도를 최적화 하는 것을 고려할만 하다.