[파이썬] Global Interpreter Lock (GIL)이란?
하나의 스레드가 두 개의 작업을 연속적으로 수행한 것에 비해, 두 개 스레드가 각각 하나의 작업을 수행했을 때 더 오래걸렸다고 합니다. 왜 이런 일이 발생했을까요?
import random
import threading
import time
def working():
max([random.random() for i in range(500000000)])
# 1 Thread
s_time = time.time()
working()
working()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
# 2 Threads
s_time = time.time()
threads = []
for i in range(2):
threads.append(threading.Thread(target=working))
threads[-1].start()
for t in threads:
t.join()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
#single 129.12857
#multi 170.34252파이썬에서 Global Interpreter Lock(GIL)이 무엇인가요?
파이썬 인터프리터가 한 스레드만 하나의 바이트코드를 실행 시킬 수 있도록 해주는 잠금기능(Lock)이다. 하나의 스레드가 작업을 끝낼때까지 모든 자원을 쓰게 두고 그 후에는 lock을 걸어서 다른 스레드는 실행되지 않도록 하는 것이다. 즉, 병렬 실행이 불가능합니다.
파이썬의 객체들에 대한 접근을 보호하는 일종의 뮤텍스 라고 할 수 있겠습니다.
- 참고로 뮤텍스란?
- 임계구역(Critical Section)을 가진 쓰레드들의 실행시간(Running Time)이 서로 겹치지 않고 각각 단독으로 실행되도록 하는 기술
GIL이 왜 필요한 것인가요?
참조 횟수에 기반하여 GC를 실행하는 Python의 특성상, Python 인터프리터가 동시에 실행되면 Race Condition이 발생할 수 있습니다. 따라서 여러개의 쓰레드가 동시에 인터프리터를 수행하지 못하도록 잠그는 것입니다.
- 참고로 Garbage Collection ( GC )란?
- 파이썬에서 모든 것은 객체이다. 그리고 각 객체는 참조 횟수를 저장하기 위한 필드를 가지고 있는데, 파이썬에서의 GC는 이러한 참조횟수를 확인하여 값이 0이 되면 해당 객체를 메모리에서 삭제시킨다.
- https://callmescone.tistory.com/399
Race Condition이 무엇인가요?
하나의 값에 여러 쓰레드가 동시에 접근함으로써 값이 올바르지 않게 읽히거나 쓰일 수 있는 상태를 말합니다. 이러한 상황을 보고 Thread-safe하지 않다고 표현하기도 합니다.
- 참고로 Thread-safe란?
- 하나의 함수가 한 스레드로부터 호출되어 실행 중일 때, 다른 스레드가 그 함수를 호출하여 동시에 함께 실행되더라도 각 스레드에서의 함수의 수행 결과가 올바로 나오는 것을 말합니다.
파이썬에서 멀티 쓰레딩이 그럼 의미 없다는 것일까요?
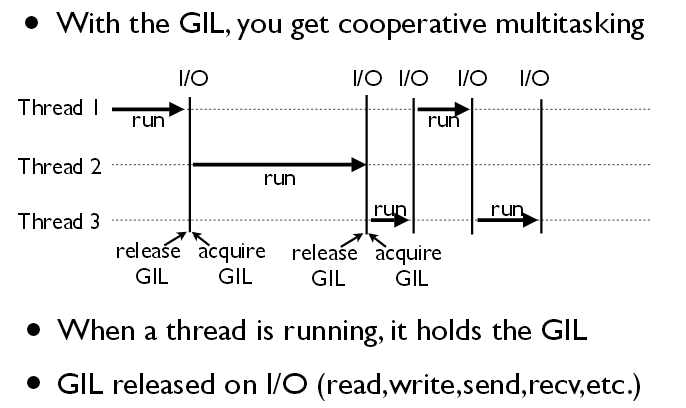
I/O 작업을 할 때는, GIL이 관여하지 않으므로 I/O 집약적인 일에는 효율적인 방식이 될 수 있습니다.
또는 threading 모듈 대신 multiprocessing 모듈을 사용할 경우, 멀티 프로세서와 별개로 메모리를 사용하여 완전히 독립하여 병렬 프로그래밍을 할 수 있습니다. 단 여러 개의 CPU가 있는 멀티코어 환경에서만 가능합니다.
- 코드 예시
multiprocessing.Process 를 사용한 예시
import time
def heavy_work(name):
result = 0
for i in range(4000000):
result += i
print('%s done' % name)
if __name__ == '__main__':
import multiprocessing
start = time.time()
procs = []
for i in range(4):
p = multiprocessing.Process(target=heavy_work, args=(i, ))
p.start()
procs.append(p)
for p in procs:
p.join() # 프로세스가 모두 종료될 때까지 대기
end = time.time()
print("수행시간: %f 초" % (end - start))
multiprocessing.Pool을 사용한 예시
import time
def heavy_work(name):
result = 0
for i in range(4000000):
result += i
print('%s done' % name)
if __name__ == '__main__':
import multiprocessing
start = time.time()
pool = multiprocessing.Pool(processes=4)
pool.map(heavy_work, range(4))
pool.close()
pool.join()
end = time.time()
print("수행시간: %f 초" % (end - start))
multiprocessing.Pool은 포크할 프로세스의 개수를 지정할 수 있다는 특징이 있습니다.
Multiprocessing 모듈을 사용하지 않고 맨 처음의 문제를 개선시킬 수 있나요?
sleep()을 사용하여 개선시킬 수 있습니다!
싱글스레드에서는 sleep으로 인해 아무런 동작도 취하지 못한 체 동작을 대기하는 반면에 멀티스레드에서는 sleep으로 멈춘 경우 다른 스레드로 context switching하여 효율이 개선된다.
- 코드
import random
import threading
import time
def working():
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
# 1 Thread
s_time = time.time()
working()
working()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
# 2 Threads
s_time = time.time()
threads = []
for i in range(2):
threads.append(threading.Thread(target=working))
threads[-1].start()
for t in threads:
t.join()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
#1 = 11.66885
#2 = 10.76572
출처
https://velog.io/@sicksong/Python-GILGlobal-Interpreter-Lock