DoLa: Decoding by Contrating Layers Improves Factuality in Large Language Models
Chuang, Yung-Sung et al. ICLR 2024
참고 :
1. https://heygeronimo.tistory.com/115
2. https://www.youtube.com/watch?v=jeml0rMTIao
3. Survey of Hallucination in Natural Language Generation (ACM 2023)
Background
- Hallucination 문제
- Contrastive Decoding
- 1) Small LM은 Large LM에 비해 짧거나, 반복되거나, 무관하거나, 흥미롭지 않은 텍스트를 생성하는 경우가 많습니다.
- 2) Large LM은 Knowledge를 비롯한 바람직한 Output을 생성하는 것에 더 높은 확률을 가하는 경향이 있습니다.
- 3) 1을 완화하고 2를 강화하겠다.
- Contrastive Decoding을 Layer 단위로 하면, DoLa
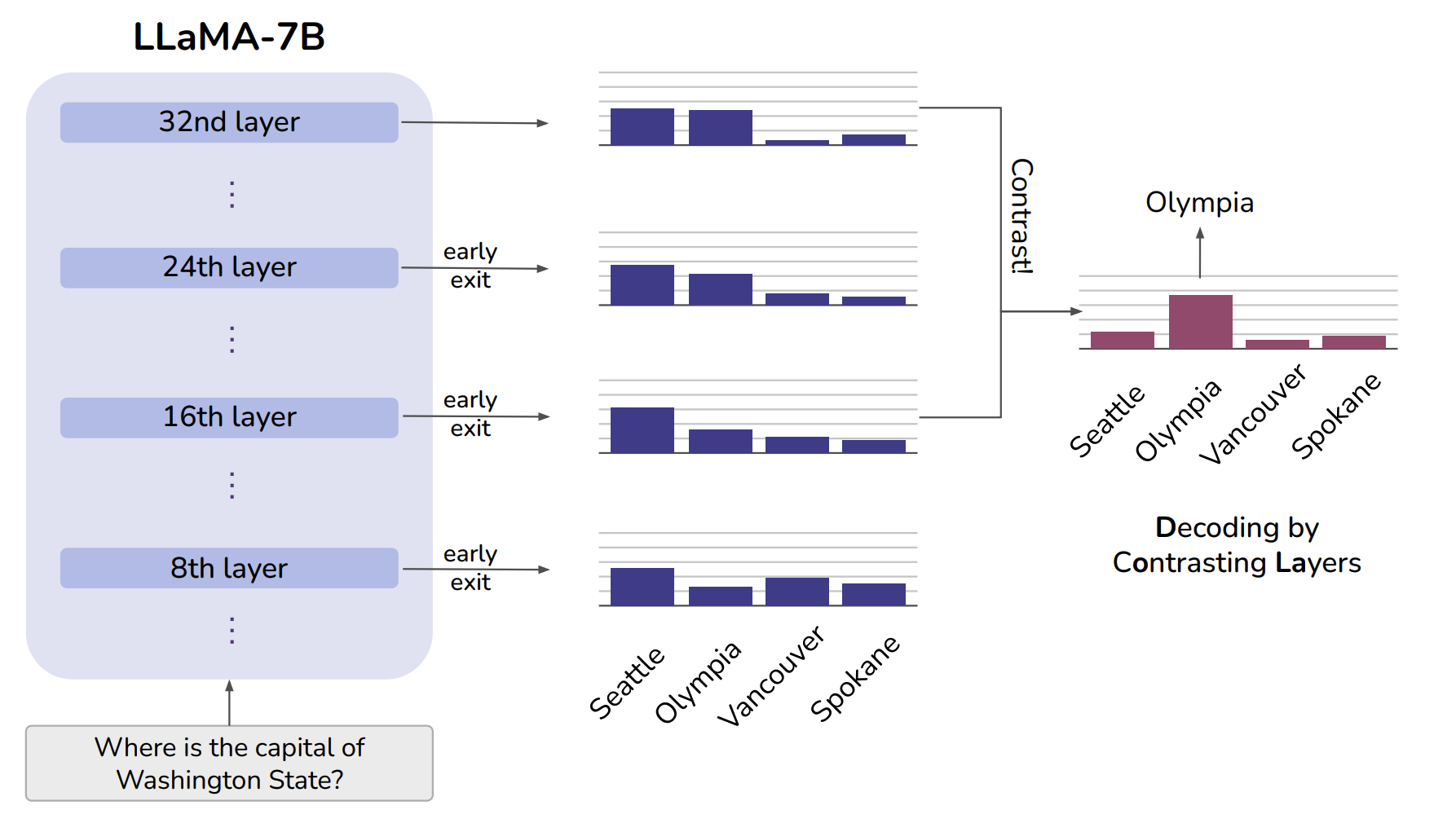
Seattle은 근거 없이 예측한 잘못된 추측이라고 볼 수 있겠고, Olympia는 Feature들을 이해하면서 얻어낸 합리적인 추론이라고 볼 수 있겠다. -> Seattle과 같은 Hallucinationd을 줄이겠다는게 위 논문의 아이디어. (별다른 Finetuning 없이도..!)
Method
Original Next Token Prediction
Original Next Token Prediction
Next Token x_t를 생성할 때 Sequence = {x_1, x_2, ..., x_{t-1}} 가
1. Embedding Layer 를 통과해 Vector로 표현
2. Transformer Layer들을 통과
3. 마지막 Transformer Layer까지 통과
4. Vocab Head 통과
5. Vocab Distribution 산출
6. Decoding 방법에 따라 Next Token x_t 생성


Early Exit
- N 개의 Layer가 있다면, 각각의 Layer에서 앞서 설명한 Next Token Prediction을 뽑아내는 것을 Early Exit이라 합니다. (Teerapittayanon et al., 2016; Elbayad et al., 2020; Schuster et al., 2022)
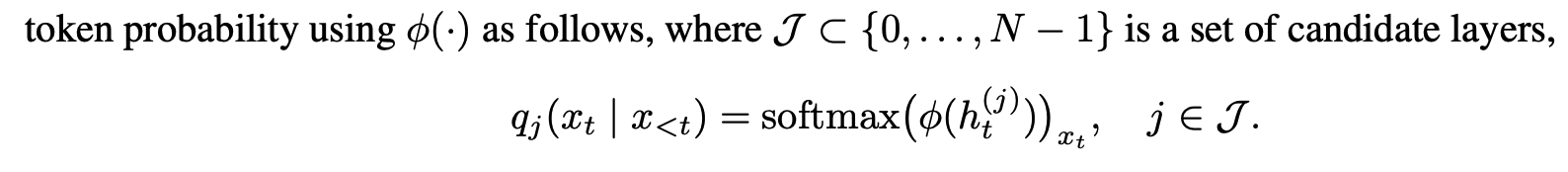
DoLa's Next Token Prediction
- Next Token Probability 산출 시 후반 Layer과 초반 Layer의 Information 을 Contrast
- M (Premature Layer) 를 정하는 정의
- d : Jensen-Shannon Divergence (JSD) - KL Divergence 두 개를 평균낸 값
- N : 마지막 레이어 (Mature Layer)
- 마지막 레이어와 Divergence가 가장 큰 레이어를 지정
- M (Premature Layer) 를 정하는 정의

사전 분석
- LLaMa - 7B (32 layer)
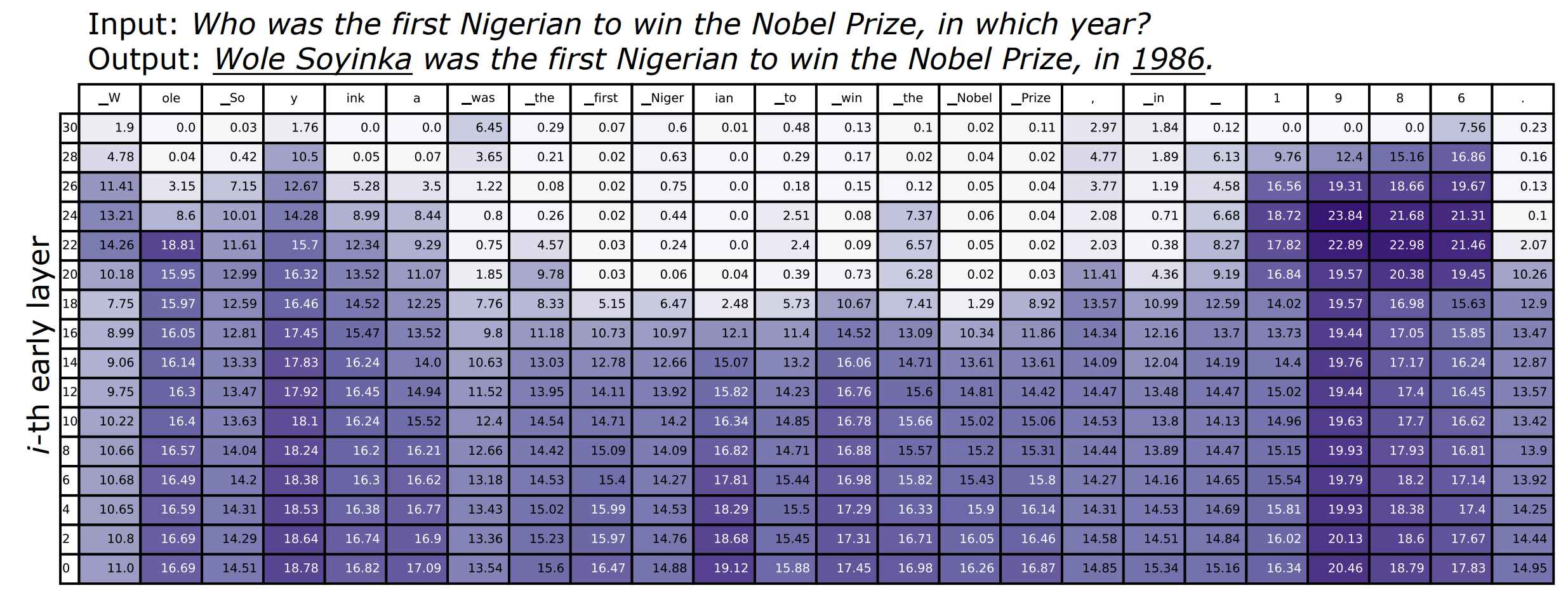
- Factual Knowledge 가 필요한 Named Entity 또는 Date를 예측할 때, JSD는 후반 Layer에서 매우 높음 ( "Wole Soyinka", "1986" ) => LM은 후반 레이어에서도 Prediction을 바꾸고, Prediction에 Factual Knowledge를 주입하는 구나.
- 기능어 또는 Input에서 복사해온 토큰 ("first Nigerian', "Nobel Prize")을 예측할 경우, 중반 Layer에서 JSD가 매우 작다. -> Model이 어떤 Token을 생성할지 미리 결정한 것으로 보임.
사전분석 결론
1. 후반 Layer에서와 같이 JSD 값이 급격히 변한 전/후 Layer를 Contrast 하면,Factual Internal Knowledge에 더 의존할 수 있을 것.
2. 동적으로 Premature Layer를 선택하는 방법이 필요.
Dynamic premature layer selection
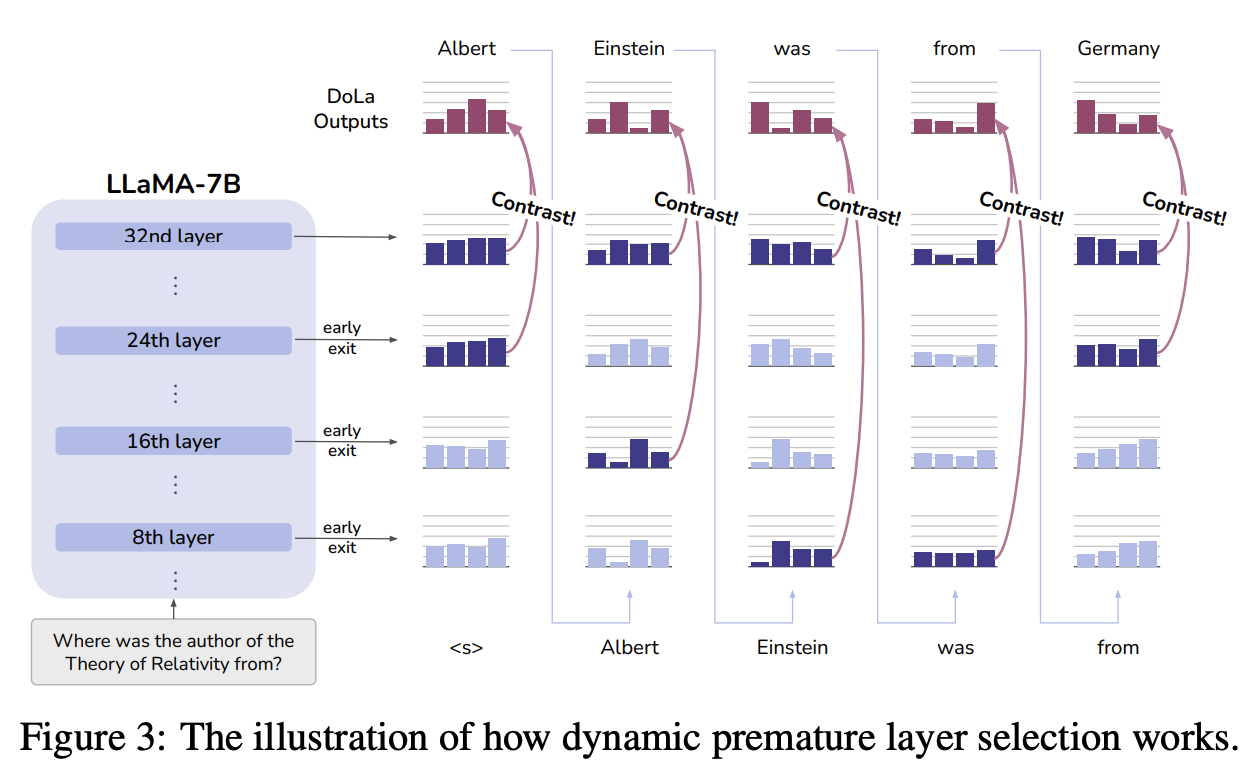
- 매 디코딩 스텝마다 최적의 Premature layer을 선택한다.

- Down Stream Task 적용 시
- Validation Set을 사용해 최적의 Bucket(J)을 선정
- Bucket 별로 Premature layer을 선택 진행
Contrasting the Predictions
- Mature Layer N과 Premature Layer M과의 Log Prob 차이 (= Next Token Prob )
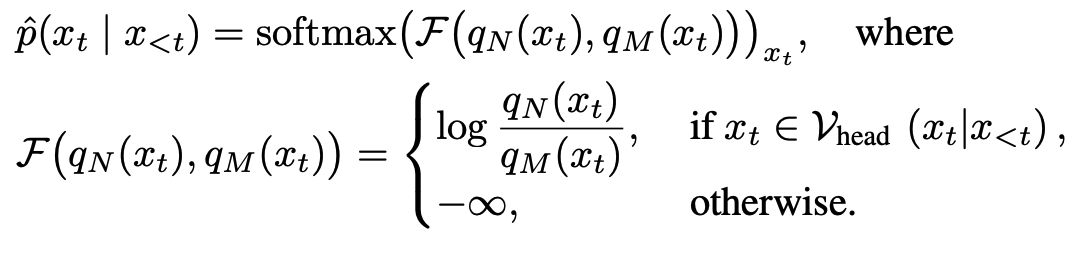
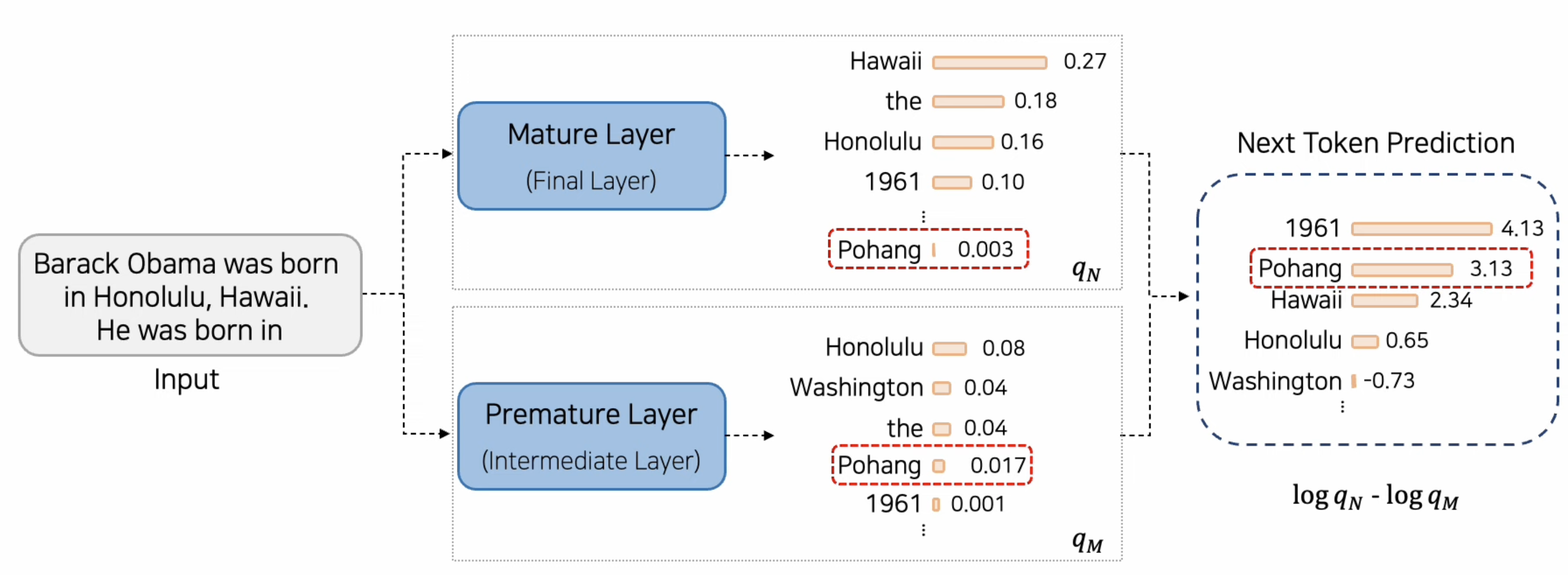
- 발생가능한 문제
- False Positive
- 타당하지 않은 토큰이 우연히 높은 Prob를 갖게 됨.
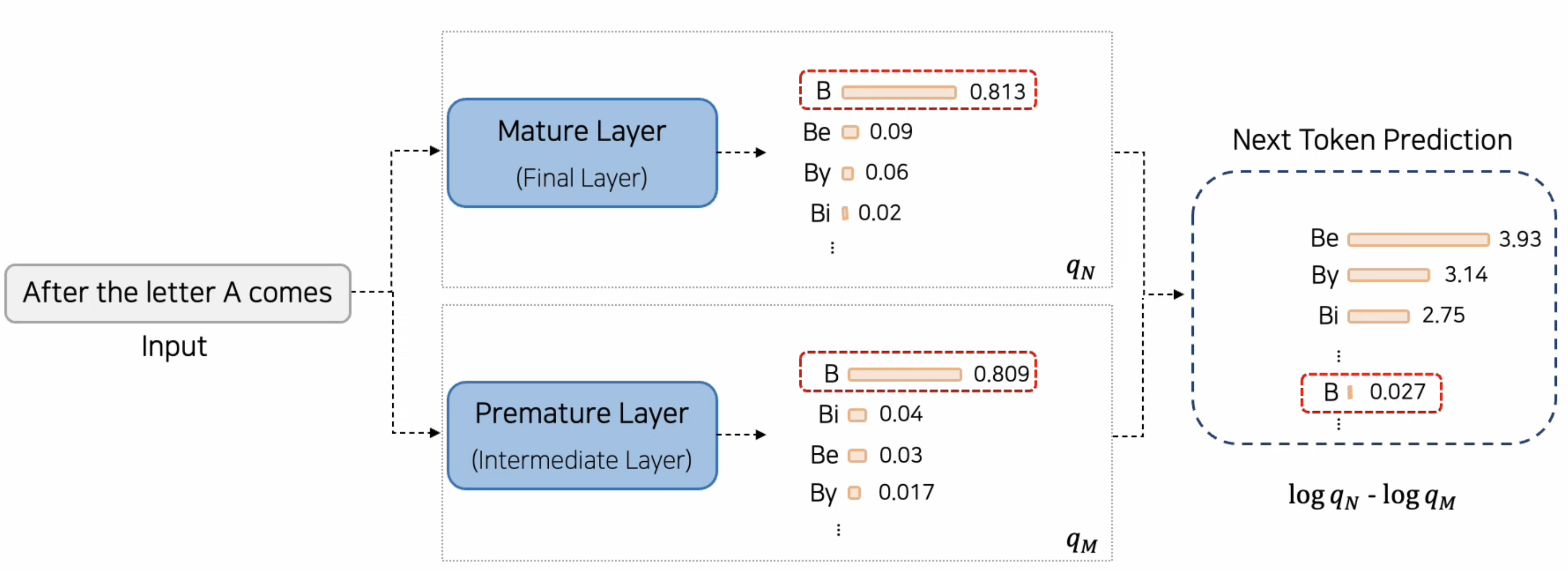
- False Negative
- 당연한 결과에 대해, Mature Layer과 Premature Layer 의 차이가 미미하면서 낮은 Prob를 갖게 되는 경우
- an adaptive plausibility constraint (APC)
- 예측 확률이 너무 낮다면, 그 토큰은 합리적인 예측이 아닐 가능성이 큽니다.
- False Positive 사례를 줄일 수 있습니다.
- 아래 식의 알파 참조
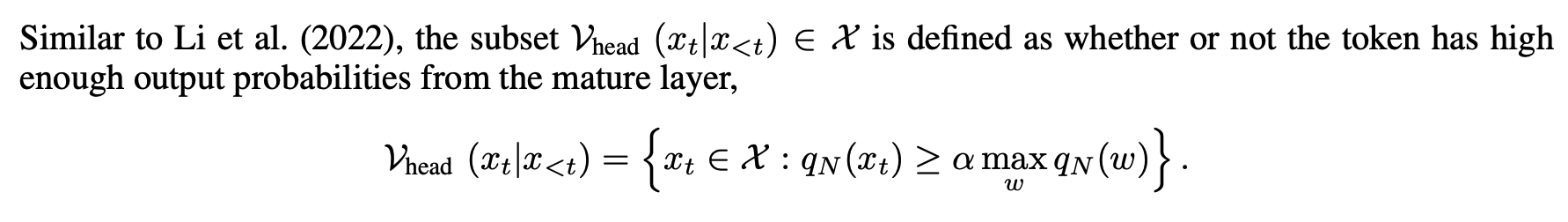
- Repetition Penalty
- introduced in Keskar et al. (2019) with 세타 = 1.2 during decode
- DoLa 가 반복적인 토큰을 출력하는 경향성을 보이고 있어 다음과 같이 설정함.
Experiments
Setting
- Dynamic Premature Layer Selection
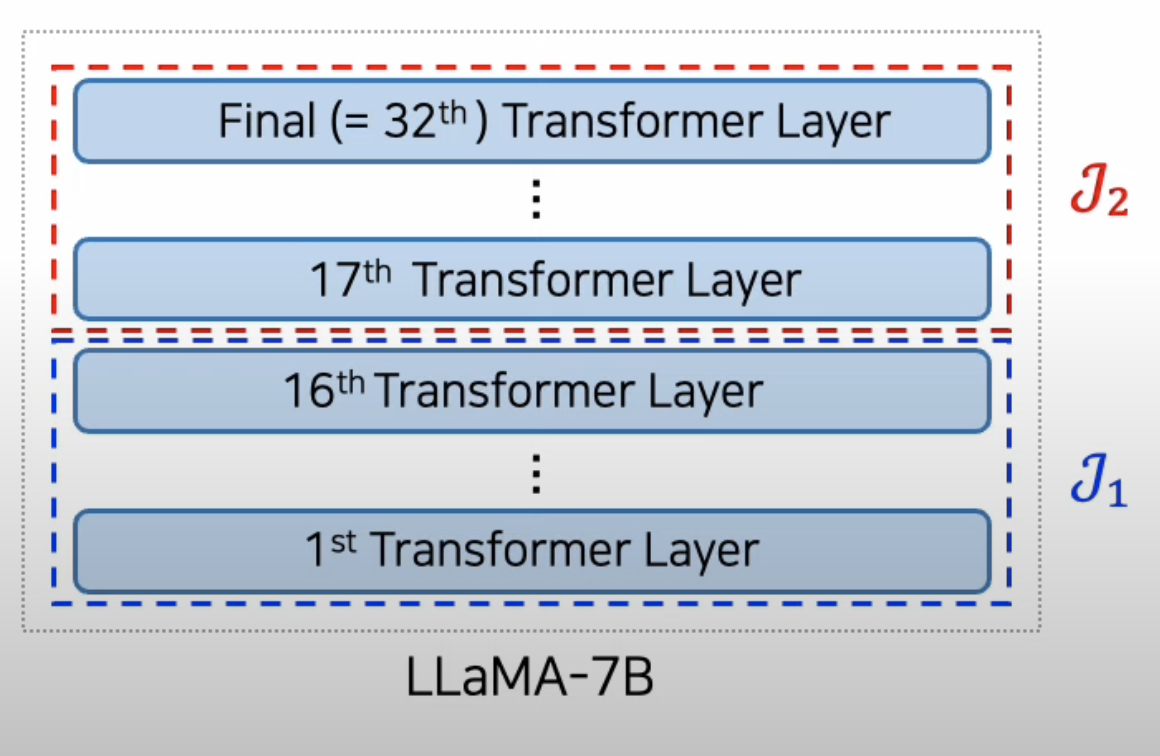
- LLaMA-7B (32 Layers) : 2 Bucket -> [0,16), [16, 32)
- LLaMA-13B (40 Layers) : 2 Bucket -> [0,20), [20, 40)
- LLaMA-33B (60 Layers) : 3 Bucket -> [0,20), [20, 40), [40, 60)
- LLaMA-65B (80 Layers) : 4 Bucket -> [0,20), [20, 40), [40, 60), [60, 80)
- 효율성을 위해 짝수 Layer 들만 후보로 사용
- Downstream Task 별 최적의 Bucket J를 찾기 위해 아래와 같이 Validation Data 사용
- TruthfulQA-MC, FACTOR : Two-fold Validation
- GSM8K, StrategyQA : GSM8K Training Set 10%
- Vicunna QA : GSM8K에서의 최적 Bucket 사용
- CD의 경우, LLaMa-7B를 Amateur로 보고 진행
Multiple Choice
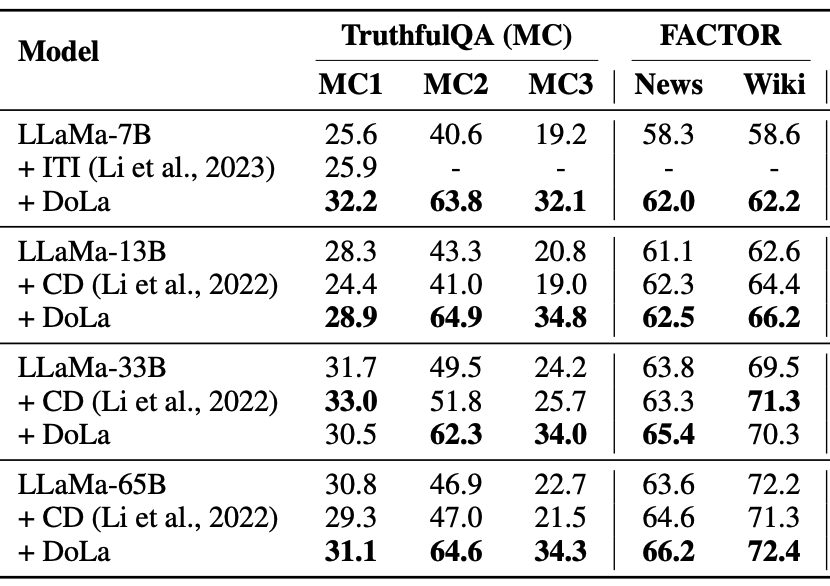
- 최적 Bucket
- TruthfulQA-MC : 7B, 13B, 33B, 65B -> 후반 Layer
- 비교적 생성할 텍스트가 짧고, Fact가 중요한 데이터셋이기 때문에 후반 Layer가 선정되었다고 추측됨.
- FACTOR : 7B, 13B, 33B, 65B -> 초반 Layer
- 길이가 긴 문장을 생성해야하는 데이터셋 ( 예측하기 쉬운 Token들이 다수 존재하는 문장 )
- 사전 분석과 유사한 결과.
- TruthfulQA-MC : 7B, 13B, 33B, 65B -> 후반 Layer
- 모든 Model Size에서 Baseline 방법론보다 높은 성능
Open-Ended Generation
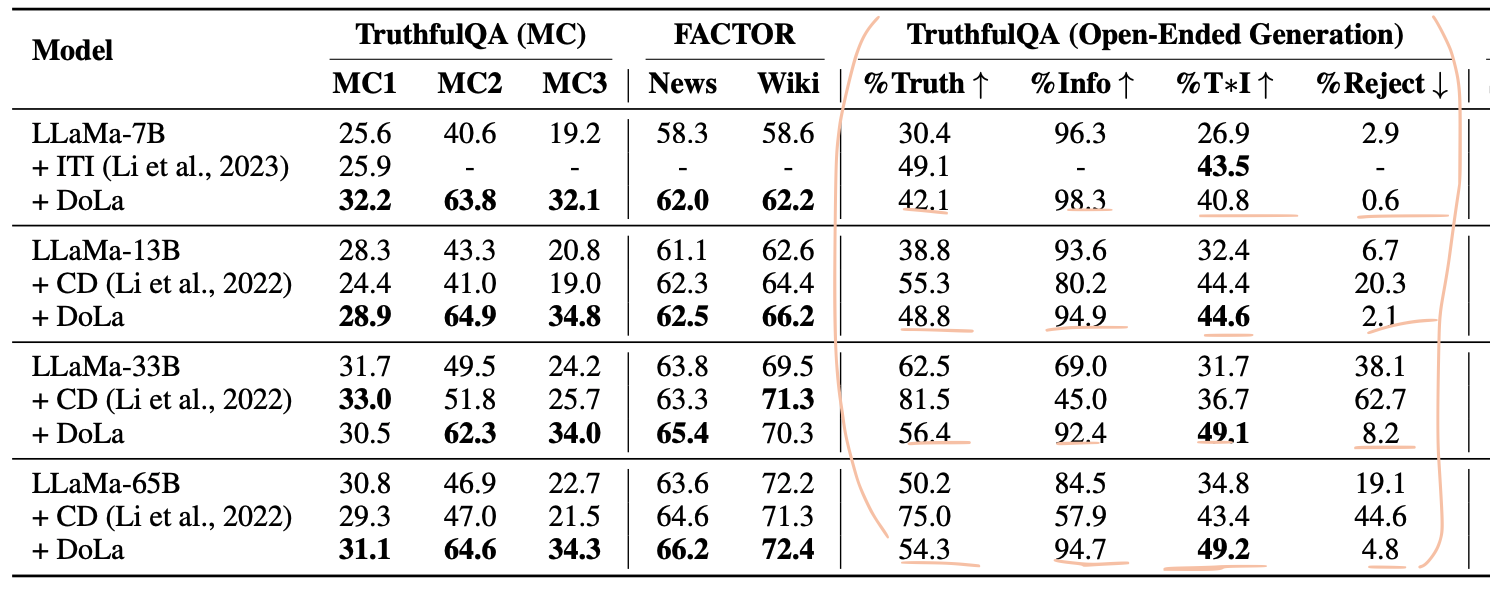
- Truthfulness & Informativeness
- Finetuning한 GPTs를 이용하여 성능 측정
- 'I have no comment" -> 진실성 100%, 정보 0%
- Truth만 높은 CD의 경우, 제대로된 답안을 못했다고 판단해야할 것 같다. (Reject 도 더 높음)
CoT - StrategyQA Result
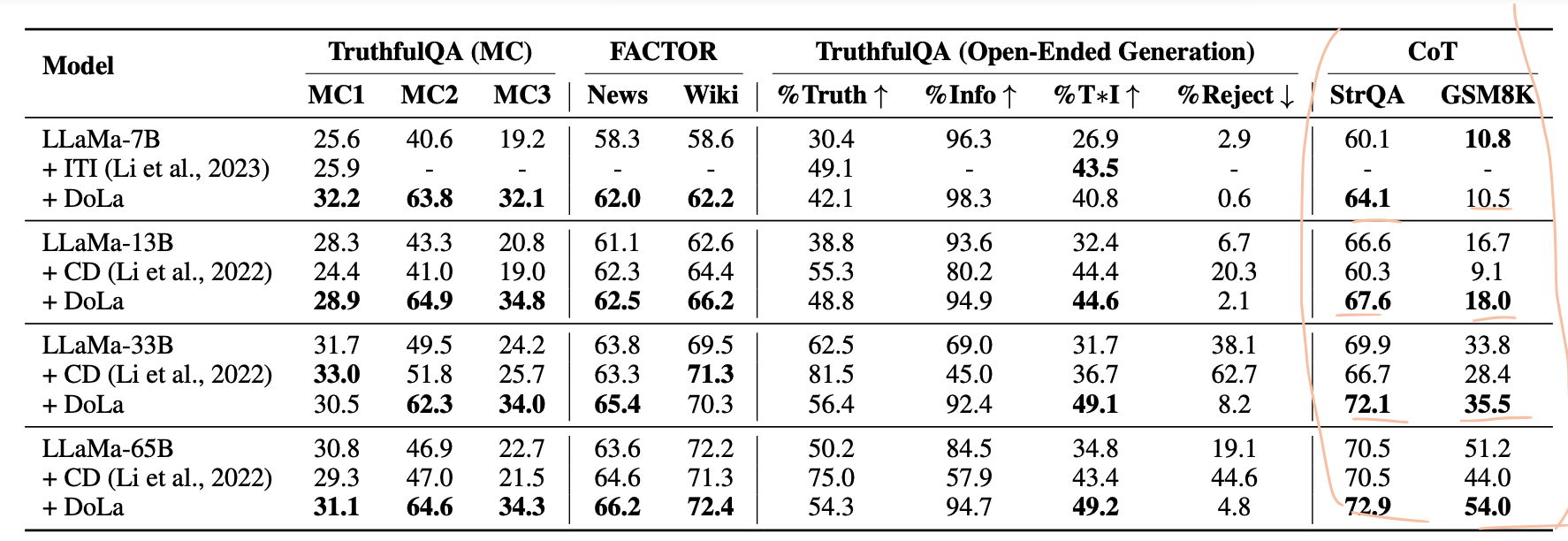
- 최적 Bucket
- 다 초반 Layer
- Contrastive Decoding의 경우, Vanilla LLaMA에 비해 오히려 성능 저하
- Small LM의 Reasoning 능력을 오히려 방해한 결과일 수 있다.
- 반면 DoLa는 약 1 ~ 3 % 가량 acc가 더 높음.
- Multi-hop Reasoning에서는 단일 모델의 다른 Layer과 Contrast 하는 것이 더 효과적이라는 결과.
Chatbot - VicunaQA (Open-ended)
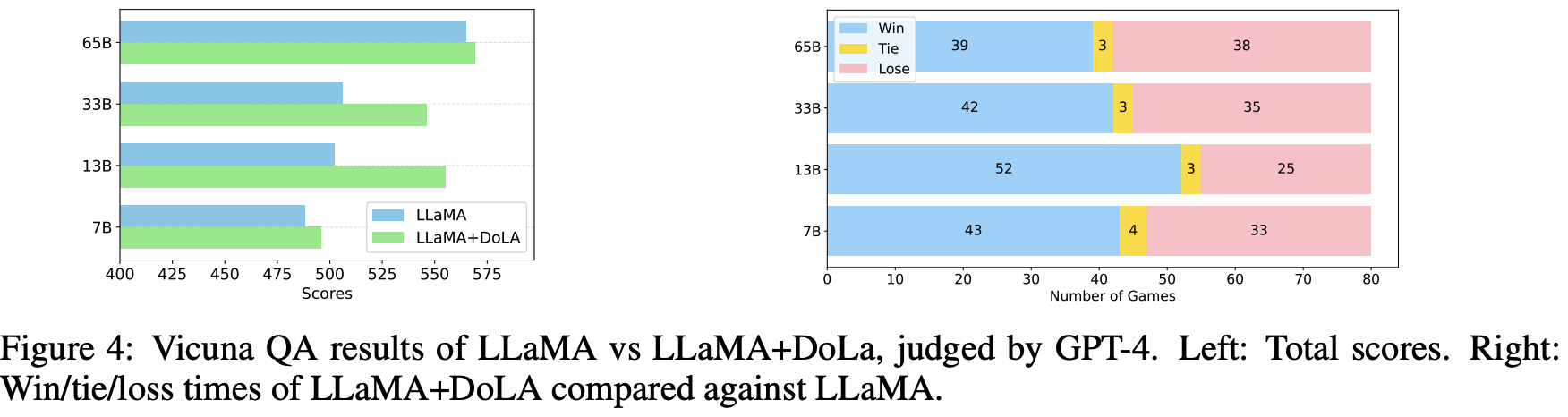
- 최적 Bucket
- 초반 Layer
- Evaluator : GPT-4
- Chatbot 에서도 DoLa가 효과적임을 보았고, 특히 13B, 33B에서 Baseline보다 크게 높은 성능을 보였다.
Static 하게 premature layer를 선택했을 때
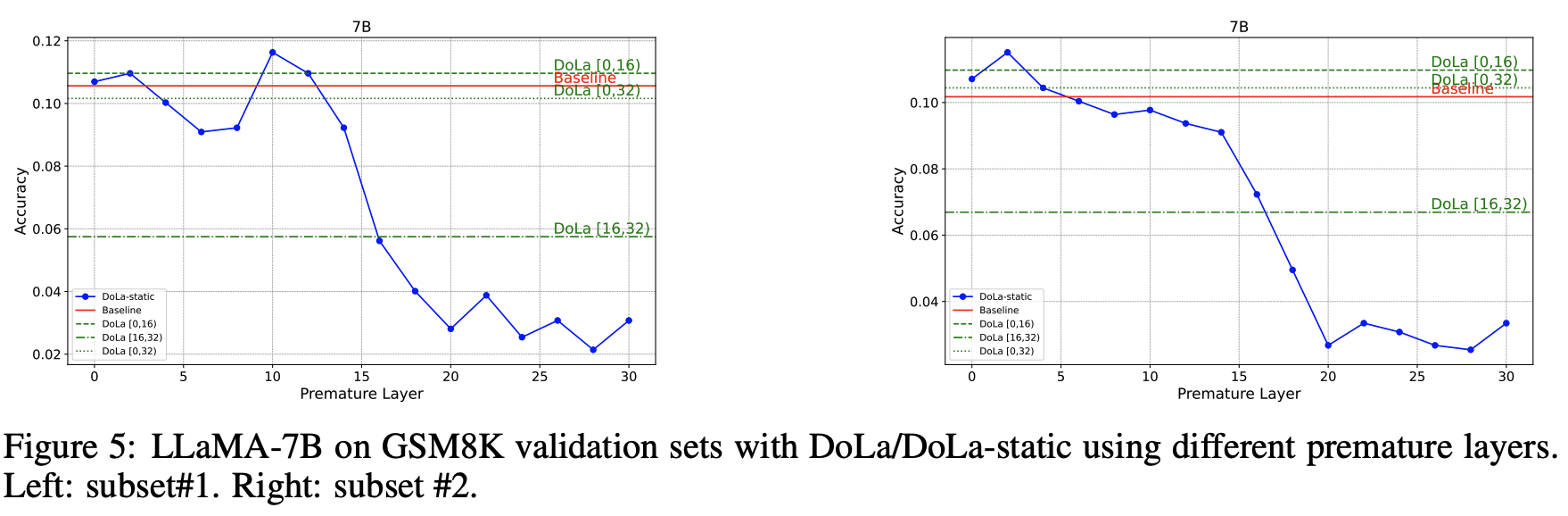
- 동일한 조건의 실험에 대해서 어떨 때는 10번째 레이어를 어떨 때는 2번째의 레이어를 선택하기도 하며 불안정한 모습을 보임.
- 고점 자체는 DoLa보다 높았지만, 고점의 레이어를 선택할 수 있다는 확신이 없다.
정성평가

Latency 비교
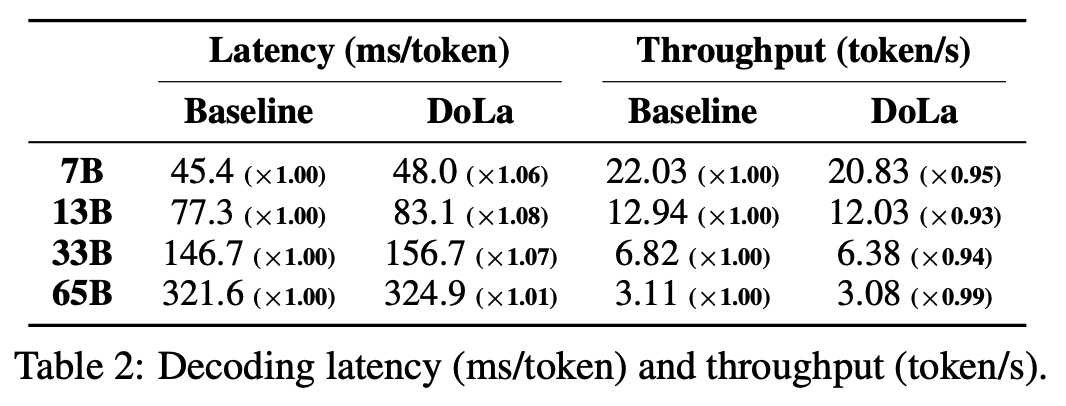
- Baseline과 DoLa 모두 Greedy Decoding 이용
- Latency가 약 1.01 ~ 1.08 배 증가
Concolusion
- Information Retrieval 또는 Model Fine-tuning 없이 다양한 Task에서 Truthfulness를 향상시킨 방법론
- Decoding 과정에서 단일 LM의 중간 Layer과 Final Layer의 Contrast를 통해 Token Prob를 수정.